
In the very beginning, I was wondering how a web server works, how mighty Apache — extremely dominating in the market at that time — was struggling with high-traffic environments, how Nginx’s event-driven architecture beautifully solved the C10K problem, and long after, how NodeJS got the community hype. At the heart of all the mentioned brands, concurrency models play a crucial role in modern web server technologies — powering most of the Internet traffic worldwide nowadays.
In this blog post, we’re going through the development of the tech tree, from a very primitive to a more advanced model that’s prevalent today. We even take a look at the infamous Python’s GIL in action, and finally find out which models are more appropriate in which situations.
Why Python? Because it’s much easier to implement examples, even the very low-level interfaces such as socket, multiplexing IO, threading… And we can use most of the cognitive energy to understand the mechanisms under the hood rather than the language itself. Let’s have some fun with Python!
Before going further, embrace yourself with this knowledge, just a bit:
- Processing / Threading
- Socket
- Multiplexing IO
The Naive server
Let’s implement a simple client-server architect, using the primitive socket() system call
|
1 import os 2 import socket 3 from datetime import datetime 4 5 # recursive Fibonacci 6 def fib(n): 7 if n < 0: 8 print("Incorrect input") 9 elif n == 0: 10 return 0 11 elif n == 1 or n == 2: 12 return 1 13 else: 14 return fib(n-1) + fib(n-2) 15 15 def handle(conn, addr): 16 p = os.getpid() 17 print("{}: [{}] Accepting {}".format(datetime.now(), p, addr)) 18 conn.send(str(fib(35)).encode()) 19 print("{}: [{}] Processed {}".format(datetime.now(), p, addr)) 20 conn.close() 22 21 def process(): 22 while(True): 23 (conn, addr) = serverSocket.accept() 24 handle(conn, addr) 27 28 26 serverSocket = socket.socket(); 27 serverSocket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) 28 serverSocket.bind(("127.0.0.1", 40404)); 29 serverSocket.listen(); 33 30 process() |
In short, the service opens port 40404 locally, which accept() connections, and returns the result of the 35th element of the Fibonacci sequence.
.
Why 35th? With it, the test machine utilizes fully 1 CPU core (out of 4) and takes approx 4s to complete the recursive function — which is suitable for demonstration.
For the sake of simplicity, I didn't paste the client code here, but it’s as simple as calling socket's connect() and recv(). Notably, 10 client processes will be forked simultaneously to connect to a server for the purpose of checking the model’s concurrency. All the codes will be included in the end.
Here comes the result:
|
# time python3 client.py |
~40s for 10 iterations of the Fibonacci function. Remember this number, because we’ll get back to it very soon. 10 requests come at once, but 1 can be served at a time, others need to wait.
It can be clearly seen that the server use blocking, serialized model, which is the simplest one of all. One process can only serve one request at a time. Is it the slowest server?
The MultiProcessing model
The naive implementation raises a question, how to scale the webserver for it to serve more concurrent requests? As one process can only serve one request at a time, the simple approach is to increase the number of processes so the service can utilize more available resources in the system (in our case it’s CPU for calculating Fibonacci). Python provides a multiprocessing library for this purpose.
|
1 for i in range(4): 2 p = multiprocessing.Process(target=process) 3 p.start() |
The code is pretty much the same as the previous implementation, just call function process() 4 times in 4 different processes using multiprocessing lib. Now we have 4 processes that can utilize fully 4 CPU cores (can be observed by the top).
|
# time python3 client.py |
Expectedly nearly 4 times faster, 4 requests were served concurrently, and the 2 last requests are serving in the last iteration, that’s why the total time is 4x3 = 12s.
The multiprocessing model is simple, appeared in the very beginning days of the webserver era yet is still prevalent in the market today with the very well-known examples of php-fpm, wsgi modules…, and even modern Apache with prefork MPM. There’re reasons to do so.
The Threading model
As all know about the disadvantages of spawning too many processes, threading comes into play. Thread is lightweight, consumes less memory, easier communication with other threads by shared memory…, but it comes with a cost of complexity and synchronization hell. Nearly everyone runs into the problem of race condition at least once in his life which is hard to debug.
Let’s try it with our demonstration, the threading library has a similar interface to the multiprocessing one, so the switching will be very simple.
|
1 for i in range(4): 2 t = threading.Thread(target=process) 3 t.start() |
The result, guess what?
|
# time python3 client.py |
4 requests were served at a time, however 4x slower in response time (~16s each). Total time ~4x multiprocessing model.
That is such a big disappointment. For our common knowledge, this result doesn’t make sense. Threading performance should be at least equal to multiprocessing if not better, but it performed in this case even worse than the single process, single thread model in the first demonstration. If you’re thinking of magical unknown stuff inside the Python interpreter, then hooray, you’re correct. It’s the so-called GIL that people usually talk about.
In short, GIL is a global process lock for keeping only one thread running in a process (the reason and details we will not cover in this post). In our case, 4 threads were running in concurrency, but only one can take the lock and utilize the CPU at a time, and each thread has a timeslice to run before being preemptively switched to another thread (sounds like OS’s CPU scheduler?).
So what threading is useful for? Let’s take one more test:
|
1 ### 2 # CPU-bound 3 def fib(n): 4 if n < 0: 5 print("Incorrect input") 6 elif n == 0: 7 return 0 8 elif n == 1 or n == 2: 9 return 1 10 else: 11 return fib(n-1) + fib(n-2) 12 13 # IO-bound 14 def sleep(n): 15 time.sleep(n) 16 ### |
Usually, there’re 2 types of applications: IO-bound and CPU-bound. For Fibonacci pure CPU is used, so the function is CPU-bound. As we previously know one Python can not utilize more than 1 CPU core because of GIL so threading will not be beneficial for CPU-bound applications. How about an IO-bound counterpart?
Let’s check the result with sleep() function (simulated IO-bound such as waiting for network/disk io)
|
# time python3 client.py |
Now thing looks normal. Threads waiting for IO won't be affected by GIL. So now you know why Python’s threading is suggested to be used on IO-bound applications only. Another reason for not using threading is a thread safety concern on synchronization, which we won't cover it here. For Python web servers, multiprocessing is still somewhat preferable.
Non-blocking?
On the above processing/threading models, the socket is blocking. This means when the thread/process is serving a request, it blocks other requests from processing and lets them wait until the socket is free again. In the non-blocking mode, the socket does not block requests, instead, returns the immediate error EAGAIN: Resource temporarily unavailable so the client won't wait. The client can retry another time and do other useful stuff rather than waiting to do nothing.
Time to build a non-blocking client. It’s quite troublesome in the beginning when we need to get familiar with something new. But trust me things will be easier as time goes by.
|
1 def clientConnect(ip, port): 2 tcpSocket = socket.socket(); 3 print("{}: Connecting {}:{}".format(datetime.now(), ip, port)) 4 tcpSocket.connect((ip, port)); 5 tcpSocket.setblocking(0) 6 7 while True: 8 try: 9 received = tcpSocket.recv(1024); 10 except Exception as e: 11 if e.errno == errno.EAGAIN: 12 print("{}: Still waiting, doing Fibonacci {}".format(datetime.now(), 31)) 13 print(fib(31)) 14 r, _, _ = select.select([tcpSocket], [], [], 1) 15 if r == [tcpSocket]: 16 print("{}: Data returned".format(datetime.now())) 17 received = tcpSocket.recv(1024); 18 print("Returned from Server: {}".format(received)) 19 break 20 21 22 clientConnect(serverIP, serverPort) |
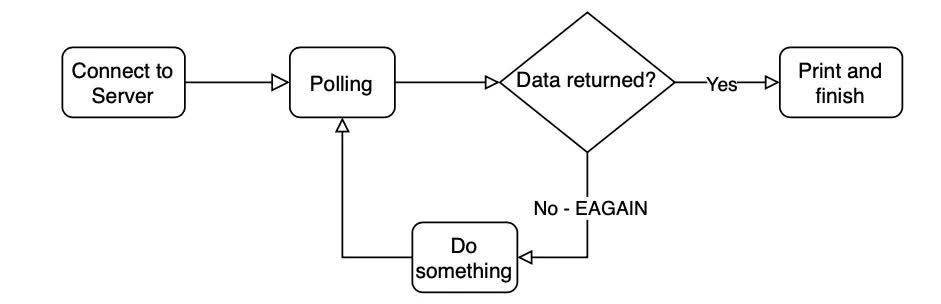
Simple non-blocking, polling algorithm
In the single thread, single process model, the client is blocking for 4s waiting for a result from the server. With non-blocking mode, we’ll try using 4s to do something more meaningful while waiting for the result. In this demonstration, only 1 request is sent to the server.
|
# time python3 nonblocking-client.py |
As can be seen, while waiting for Fibonacci(35), the client take the time to calculate 3x Fibonacci(31) (~1.5s/each)
Non-blocking mode is very useful for IO-bound tasks, asking the process can use the time waiting to do other tasks, without the need for threading or subprocess. Operating systems support polling mechanisms called Multiplexing IO with the syscalls select(), poll(), epoll(), kqueue()… which helps non-blocking programming becomes more popular.
The asynchronous, non-blocking Event-driven architecture
The non-blocking demonstration above is a bridge to the last model, which is the heart of the most effective, prevalent, prominent web servers these days such as Nginx, NodeJS, Lighttpd… The technology is called event-driven architecture, and the core of the architecture is an Event Loop. Simply put, an event loop is a loop inside a process, which triggers callbacks based on events.
Think of the state machine like the rules for chess. Each HTTP transaction is a chess game. On one side of the chessboard is the web server — a grandmaster who can make decisions very quickly. On the other side is the remote client — the web browser that is accessing the site or application over a relatively slow network.
— Inside NGINX: How We Designed for Performance & Scale
An application does not block events, that’s why it’s non-blocking and possible to accept a lot of requests simultaneously. Requests will be put into a run-loop and then processed asynchronously until completion. Event loop can be very fast, but with a single-threaded nature, one single blocking call will block the whole process, which causes all the accepted requests blocked as well. We won't go into too many details here, because it may take several days to talk clearly about the event-driven architecture. Time to make some codes!
Python supports event loops with a high-level interface called asyncio library. The syntax itself is quite difficult for ones not familiar with event-driven beforehand, but let’s just focus on ideas, not the language itself.
|
1 import os, sys 2 import socket 3 import asyncio 4 import time 5 from datetime import datetime 6 7 # CPUbound 8 async def fib(n): 9 if n < 0: 10 print("Incorrect input") 11 elif n == 0: 12 return 0 13 elif n == 1 or n == 2: 14 return 1 15 else: 16 return (await fib(n-1)) + (await fib(n-2)) 17 18 # IObound 19 async def sleep(n): 20 await asyncio.sleep(n) 21 22 async def handle(conn, addr): 23 p = os.getpid() 24 print("{}: [{}] Accepting {}".format(datetime.now(), p, addr)) 25 #await loop.sock_sendall(conn, str(await sleep(4)).encode()) 26 await loop.sock_sendall(conn, str(await fib(35)).encode()) 27 print("{}: [{}] Processed {}".format(datetime.now(), p, addr)) 28 conn.close() 29 30 async def start_server(): 31 server = socket.socket(); 32 server.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR | socket.SO_REUSEPORT, 1) 33 server.setblocking(False) 34 server.bind(("127.0.0.1", 40404)); 35 server.listen(); 36 37 while(True): 38 #print( asyncio.all_tasks() ) 39 conn, addr = await loop.sock_accept(server) 40 loop.create_task(handle(conn, addr)) 41 42 loop = asyncio.get_event_loop() 43 loop.set_debug(True) 44 loop.run_until_complete(start_server() |
Similar to the threading model, we will test the server with CPU-bound and IO-bound functions.
IO-bound first, where event-driven shines the most. As usual 10 requests came to the server instantly.
|
# time python3 client.py |
All requests were accepted at once, and they finished at the same time. The total time is 4s, which means the concurrency performed pretty nicely.
Next, CPU-bound, expectedly, the server uses only 1 process, so the CPU utilization could not go higher than 1 core, eventually, the response will be slow. How slow actually?
|
# time python3 client.py |
24s for one request, and it was even running sequentially. Simply the fib() was blocking the loop, causing the whole process to stall. The event loop model is unbelievably slow when handling CPU-bound tasks, most interesting is that it’s even much slower than the single process, single thread model. This result proves that the event loop is not always a silver bullet for everything, and we need to use it with care. Remember back in the days when is Nginx having a lot of mysteries related to blocking issues?
***
We’ve gone through so much code and models, we’ve seen how GIL hindered threading performance, and we’ve seen the power of well-known event-driven architecture as well as the disadvantages. Concurrency is difficult, but fun to play with. About the applicability of each mechanism, I hope that you can find out by yourself after the long examples, and write better codes. Have fun concurrency!
***
Further readings
- https://github.com/wintdw/webserver.git
- Chapter 63 Alternative IO Models — The Linux Programming Interface — Michael Kerrisk
- https://www.aosabook.org/en/nginx.html
- https://www.nginx.com/blog/thread-pools-boost-performance-9x/