
Introduction
Recently, I happened to hear about "Redis Stack", which piqued my curiosity, so I tried to find out more about it.
Like what is called, it is the stack for Redis. To simplify this, the stack will contain modules for separate purposes, such as RedisJSON, RediSearch, RedisGraph, RedisTimeSeries, and RedisBloom.
Surely all of the people who make web applications have also used Redis as a cache layer to help speed up your application.
Here is a typical example of setting cache in Redis:
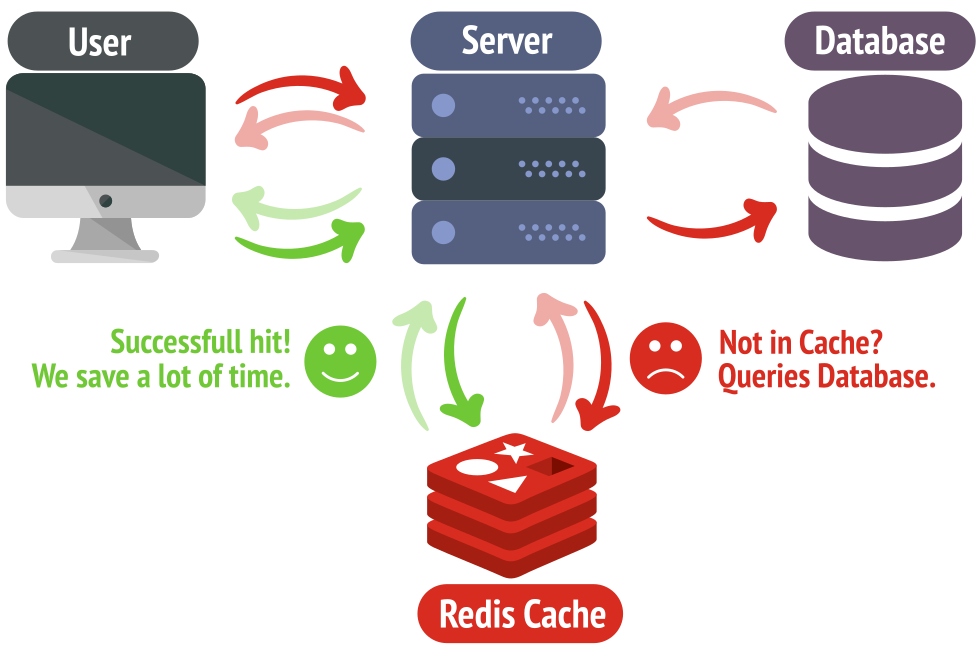
The short explanation for the above model is that we will prioritize getting data from the cache. If the cache data does not exist, we will get the data from the database and then update it back into the cache.
However, when working with cache, sometimes we need to store JSON data. The existing data types in Redis include only strings, hashes, lists, sets, bitmaps, sorted sets, hyper logs, and geospatial indexes. As usual, we will have to serialize JSON data to string to save.
Storing JSON data as a string can be difficult for the application.
Because to store that data as a string, we have to serialize the data before saving. Also, when we need to get the information of a field in the data part, we are forced to get the entire data, then deserialize it to get the original JSON object, update it, and serialize it again before storing it.
Pretty complicated, isn't it? But it isn’t stopped here. When a single field in the object needs to be updated, the above process is repeated.
The solution
To avoid these disadvantages and improve the experience for developers when working with cache, Redis stack offers us a module called RedisJSON - which allows us to access and store JSON data instead of just storing strings like the traditional.
Sounds perfect, right? :D
But nothing is perfect, and so is RedisJSON :D. It will cost us if we abuse it.
Take a look at the two pictures below to see the difference:
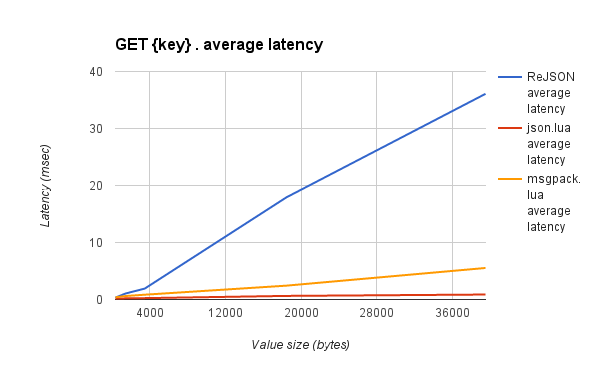
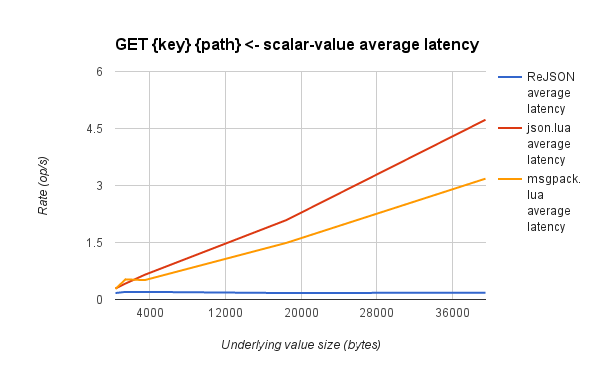
- About performance: The advantage is that updating the sub-elements of a document is faster than manipulating a string, which contains a serialized JSON object. But retrieving and saving the entire document will cost more than those actions with string.
- About maintainability: Using some native data types in Redis for your JSON object can be efficient, but the code will be more complicated to maintain. There may be additional migration/refactor work when the structure of the document is changed.
Making real work
Next, let’s us have real experience with RedisJSON.
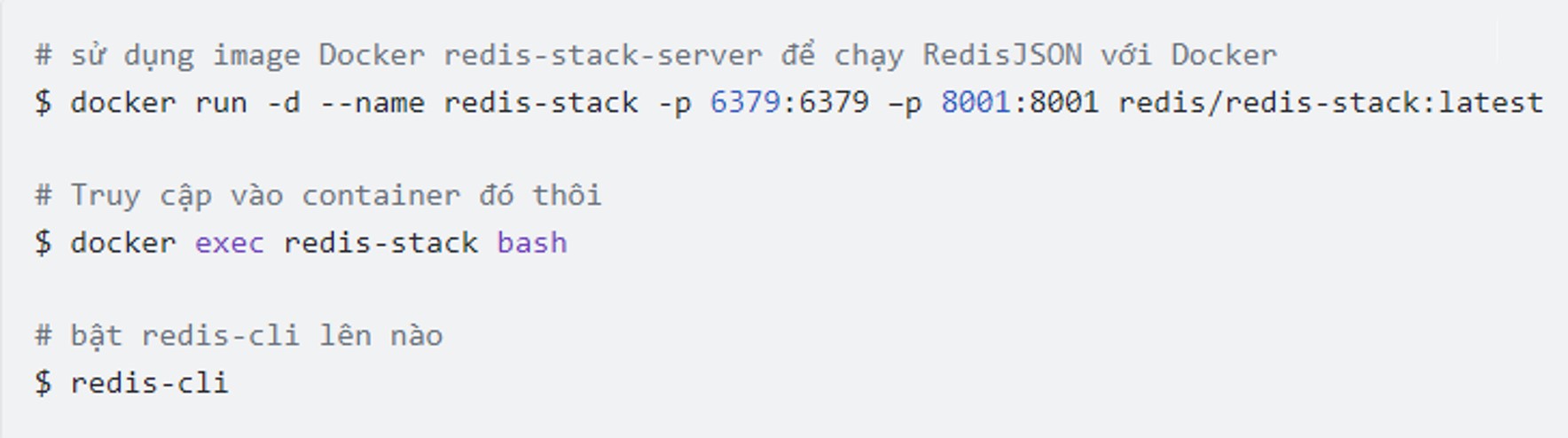
We will try to operate the GET/SET/DEL
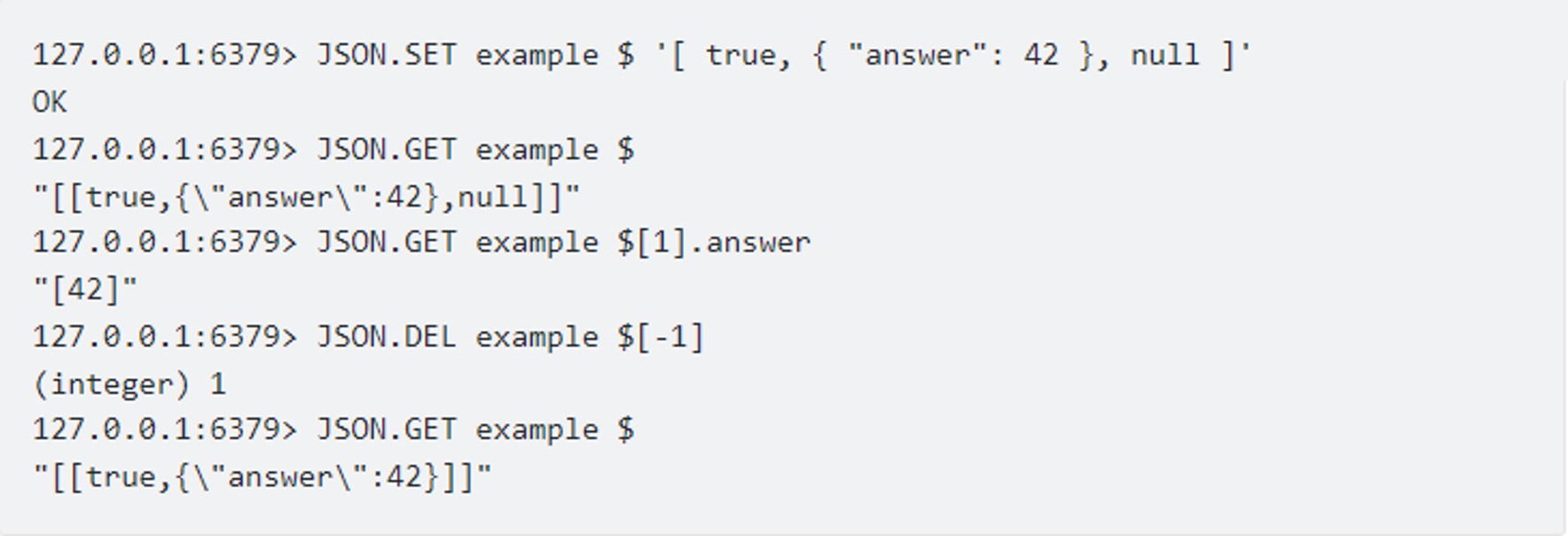
Well, it’s simple, isn’t it?
Well, it’s long enough for this time. With an upcoming blog, I will introduce you to full-text search in Redis. See you then!
Reference
[1] https://redis.io/docs/stack/
[2] https://redis.io/docs/stack/json/performance/#comparison-vs-server-side-lua-scripting