
This study is a part of the research on Ceph’s IO subsystem acceleration and is mostly applicable to the Ceph-specific IO workload.
In some discussions around the internet, people suggest different settings for the drive’s write cache, but there is no complete study detailing the effect of the write cache on the performance of the disk subsystem.
***
Let’s figure out what is write cache first.
Write cache using a volatile (RAM) memory in a disk drive for the temporary storage of written data. Disk cache (usually 64–128MB nowadays) is used for reads (read-ahead) and writes.
When the write cache is enabled (default), the host writes come to the write cache first, if there are no additional flags provided, then flushed to the storage media (plates/NAND) in the background.
Write cache Pros:
HDD: data can be re-organized before writing, sorted, and flushed to the plates in chunks, allowing NCQ to work efficiently and spend less time on seeks.
SSD: theoretically, reducing write amplification and NAND cell wear, improving drive’s lifespan. SSD can’t rewrite a single 4k page, they have to rewrite a whole block for that, which is usually much bigger than a page. Write cache may organize written data into bigger chunks, reducing the amount of actually written data.
Write cache Cons:
Write cache is a volatile memory, so written data can be suddenly lost during a power loss.
There are 2 ways to control the persistence of written data to the storage media from a write cache:
https://www.kernel.org/doc/Documentation/block/writeback_cache_control.txt
a) FLUSH CACHE command to the disk drive, instructing it to flush all the data from the volatile cache to the media. Controlled by setting REQ_PREFLUSH a bit.
b) FUA bit, which is more granular, and works just for specific data. Controlled by REQ_FUA bit.
https://en.wikipedia.org/wiki/Disk_buffer#Force_Unit_Access_(FUA)
Top-grade SSDs come with super-capacitors (kind of BBU for RAID adapters with onboard cache), allowing cached data to be flushed after the power loss, so they can simply ignore FLUSH CACHE / FUA, pretending that they do not have a volatile cache, and showing higher performance.
So, let’s figure out how the write cache affects IO performance with a different write pattern.
To find it, I tested HDD/SSD disks with enabled/disabled write cache, and different sync settings (async/fsync/disabled).
Test stand:
HDD:
|
Model Family: HGST Ultrastar 7K6000 |
SSD:
|
Model Family: Samsung based SSDs |
CPU: 2x Intel(R) Xeon(R) CPU E5–2630 v4 @ 2.20GHz
MEM: 8x32GB DDR4–2400 @2133 MT/s
MB: X10DRi
HBA: MB embedded SATA controller: Intel Corporation C610/X99 series chipset sSATA Controller, AHCI
—
We’ll use fio with the following default settings:
# fio -ioengine=libaio -direct=1 -invalidate=1 -bs=4k -runtime=60 -filename=/dev/sdX
and changing:
-fsync=1 - doing fsync() calls after each write, triggering FLUSH CACHE (also tested with -fdatasync, there are no differences in the final results)
-sync=1 - opening block device file with O_SYNC, setting FUA bit for each write
-rw=randwrite|write - random/sequential write patterns
-iodepth=1|128 - 1/128 IO threads to emulate single- and multithreaded applications
Results:
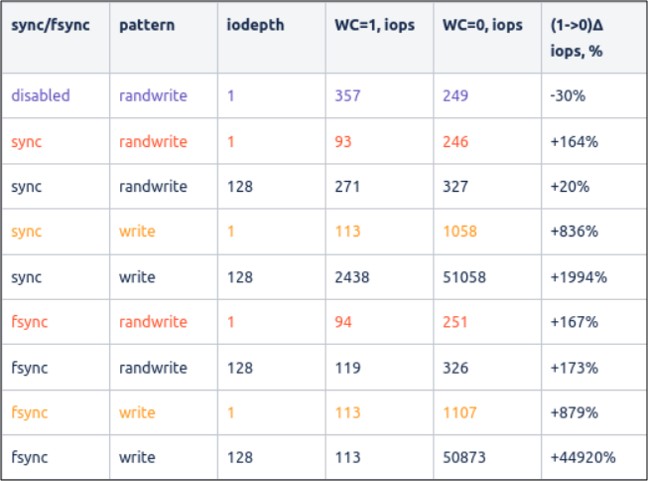
HDD:
SSD:
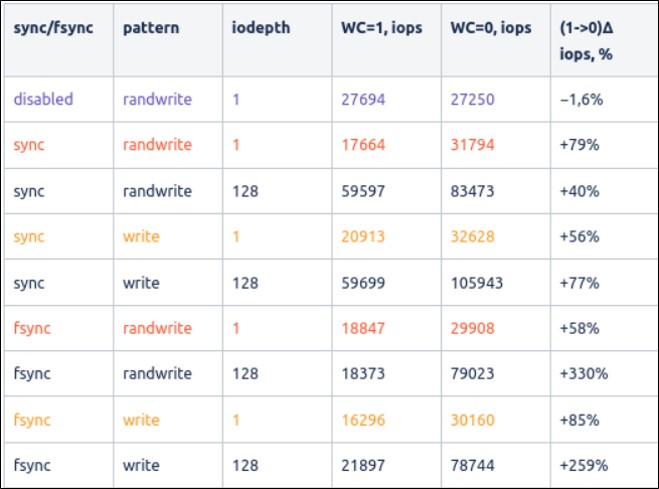
IO pattern is divided into 4 groups for easier comparison:
- baseline (purple) — direct (unbuffered) writes with no sync flags set. Worst case due to single-threaded random writes, when OS scheduler doesn’t work, and optimizations can be done by the drive only.
- journal write (yellow) — load pattern similar to journal write, worst values over sync/fsync should be taken
- worst case (red)— single-threaded random writes when writes cannot be merged by OS scheduler and dispatched to the drive “as is”. Should be compared with baseline values.
- other groups with multi-threaded random/sequential write show the cases when the OS IO scheduler can work effectively and organize IO requests into bigger blocks before dispatching to the device, which works especially effectively in the case of multi-threaded sequential writes (that’s why we have such a weird high number).
As we can see, disabling the write cache gives a noticeable performance boost for writes, performed with fsync()/sync()
***
Let’s take a look at what writes look like on the block level with a different cache setting.
Write cache is enabled:
O_SYNC:
[pid 1688687] openat(AT_FDCWD, "/dev/sdc",
|
WFS here is a REQ_WRITE with the REQ_FUA flag set
We can see that there is no additional flush request happening after the write is completed, and this way of persisting data into the backing media works faster than writing and following the whole buffer flush.
fsync()/fdatasync():
[pid 1697421] openat(AT_FDCWD, "/dev/sdc", O_RDWR|O_DIRECT|O_NOATIME) = 5
|
Here we can see that after a successful write operation, fio issuing fsync() call, forcing the drive to perform FLUSH CACHE.
FWS here is REQ_PREFLUSH | REQ_WRITE | SYNC
Thus, for each write operation with fsync() / fdatasync()
a) two independent operations (write/flush) issued to the device, each has to be received, queued, dispatched, and handled by the process. All of this adding and overhead and reduces the performance
b) whole write cache flushing operation may cause a significant write amplification, and the rotational disk drive may have to handle plenty of random writes to flush the write cache, making this operation pretty slow
Write cache is disabled:
O_SYNC:
8,32 39 136 0.620358451 1680674 P N [fio]
|
fsync()/fdatasync():
8,32 21 1185 1.355483245 1702607 P N [fio]
|
As we can see, write patterns are similar now, the same as the performance with those options.
No Fflags present, no FUA bit set or FLUSH CACHE initiated, writes comes directly to the media, without caching.
***
Analyzing the results:
HDD:
a) As we can see for non-sync operations, even for single-threaded random writes, enabled write cache actually helps to increase the performance, since write requests coming to the quick volatile memory (RAM) first, then can be re-organized by NCQ, flushed in batches, allowing the device to reduce IO time and increase the performance capacity. With disabled write, cache performance degrades to the level of sync writes, which is expected.
b) With O_SYNC / fsync() enabled, write cache adding more overhead, reducing the performance. Disabling the write cache increases the performance since no additional write/flush cache operation is requested → no overhead.
c) O_SYNC / fsync() with the write cache disabled are identical, since on the block layer they are translated to the same commands.
d) O_SYNC / fsync() performance with enabled write cache is different for 128-threaded writes, with O_SYNC performance is higher, since each thread setting FUAbit independently and “touching” only its data, not all the data in the write cache, which adds less overhead and increases the performance, both for random and sequential writes.
SSD:
The picture is pretty much the same as for HDD, due to the similar logic, but the scale is different because of the higher performance of NAND memory in comparison with rotational media.
a) for non-sync writes, disabling the write cache reduces performance just a bit for the single-threaded workloads. For multithreaded workload performance drop may be more significant, also, since storage layer performance depends on many factors (like a garbage collector in action, lack of free writable blocks, worn NAND cells, and the way NAND cells are organized (MLC/TLC/QLC)), performance drop may differ within wide limits. We should consider this particular SSD drive results just as an example only, for other drives it will be different.
b) Disabling the write cache gives a noticeable performance boost, not that big as for HDD, since NAND cells are still pretty fast and the overhead for cache flushing is not that big.
***
Conclusions:
1) Writes with FUA bit set seem to work in Linux. It’s better to use it rather than fsync()/fdatasync() because:
a) it’s more fine-grained and makes less overhead and write amplification.
b) can be used even with enabled write cache, to get the write cache benefits for non-sync workload, and make sure that data with O_DIRECT is safely flushed to the media for specific files.
2) For workloads where fsync()/fdatasync()/O_SYNC is the major part, disabling the write cache will give a significant performance boost for HDD. For SSD as well, but by sacrificing its lifespan and durability since it will lead to higher write amplification (theoretically, we didn’t test it carefully). Disabling write cache for SSD may be considered for having maximum performance when lifespan is not important.
***
Practical application
Applying all these pieces of knowledge for Ceph, I tested OSD performance, created in different ways, with different write cache settings.
To test real OSD performance (not under some particular applications like RBD or CephFS), I used Ceph OSD bench like the following:
# ceph tell osd.X bench 268435456 4096
where
268435456 - the payload size
4096 - IO block size
It’s making single-threaded writes with a defined block size (default 4M).
I ran tests with 4k block and 4M block.
OSDs were configured in 3 options:
a) HDD only
b) SSD only
c) data on HDD + WAL/db on SSD
Results:
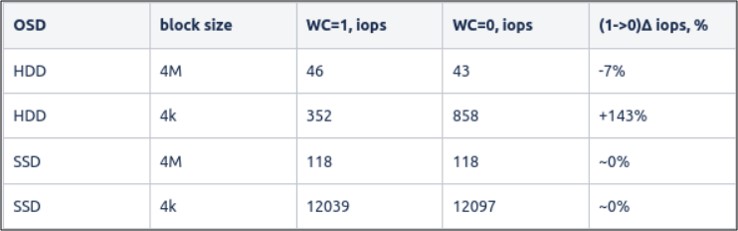
HDD, SSD:
OSD on HDD+SSD(WAL), different write cache configurations
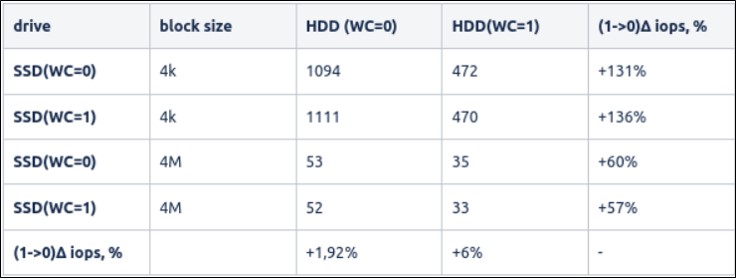
As we can see from the results, disabling the write cache on HDDs can improve its performance, both with small and big blocks.
Disabling the write cache on SSDs doesn’t give a significant boost in any configuration, so we can keep it enabled and save the SSD drive’s lifespan.
OSD processes using fdatasync() calls after each writing, for both journal and data. Since it’s using disk drives exclusively, disabling the write cache leads to better performance, as shown in the tests above.
***
Thanks for reading :)