
Part 02
Introduction
Nowadays, more and more users read news online from multiple sources where they are bombarded with millions of articles. To help readers explore their favorite content more straightforwardly, at each website, a writer or editor will assign an article based on its content into some predefined main categories like Entertainment, Game, Sport, or so. Nevertheless, each website has its own hierarchical category, for instance, 12 main categories at Zingnews against 10 main categories at Vnexpress, making our News Recommendation System using crawled articles hard to identify user preferences, organize and distribute the right content to the right users. Consequently, standardizing categories along with classifying millions of news automatically play a vital role in Cốc Cốc Newsfeed - The Personalized Recommendation System where the output of our news categorization model is used for myriads of services (please refer to our first blog for the overall architecture). This blog will highlight the major challenges along with our solution and demonstrate the essential steps of building the news categorization model.
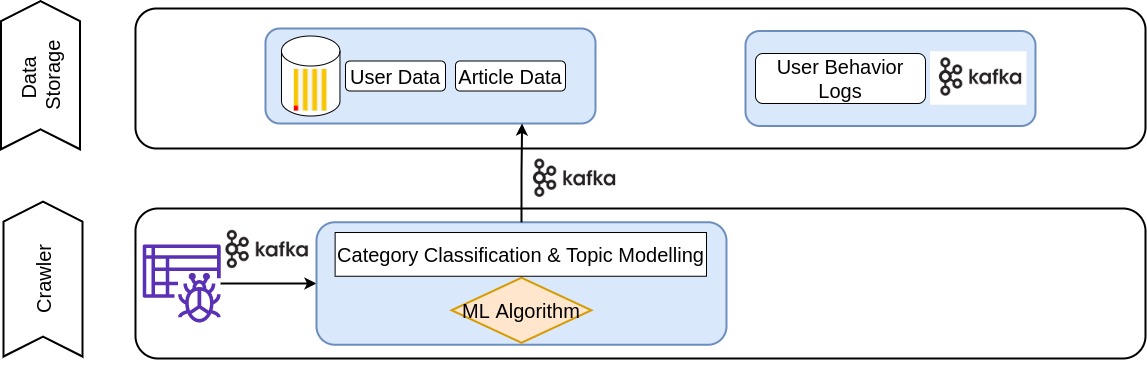
The news categorization model in the News Feed Recommendation system
Datasets
Like other supervised machine learning algorithms, in order to build a news categorization model, a training dataset is a prerequisite. Back in April 2020, when the project started, our mission was to build the first version of the classifier in the haft of the month. Waiting for sufficient crawled data was not feasible since it could take a couple of months. Another solution was seeking available data on the Internet. Finally, we ended up with 50Gb uncompressed news data (about 14 million crawled articles from various sources) which is well-organized and categorized into 13 categories in advance at GitHub - binhvq/news-corpus: Corpus tiếng việt. Each article consists of many valuable attributes such as title, publish date, tags, content, etc in which title, sapo (description), content, and cate (category) are the most important information for the classification task.
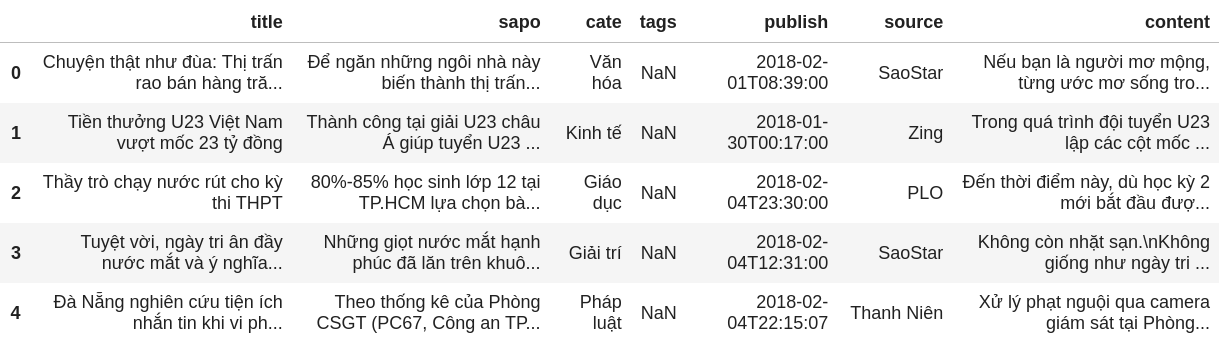
Article metadata
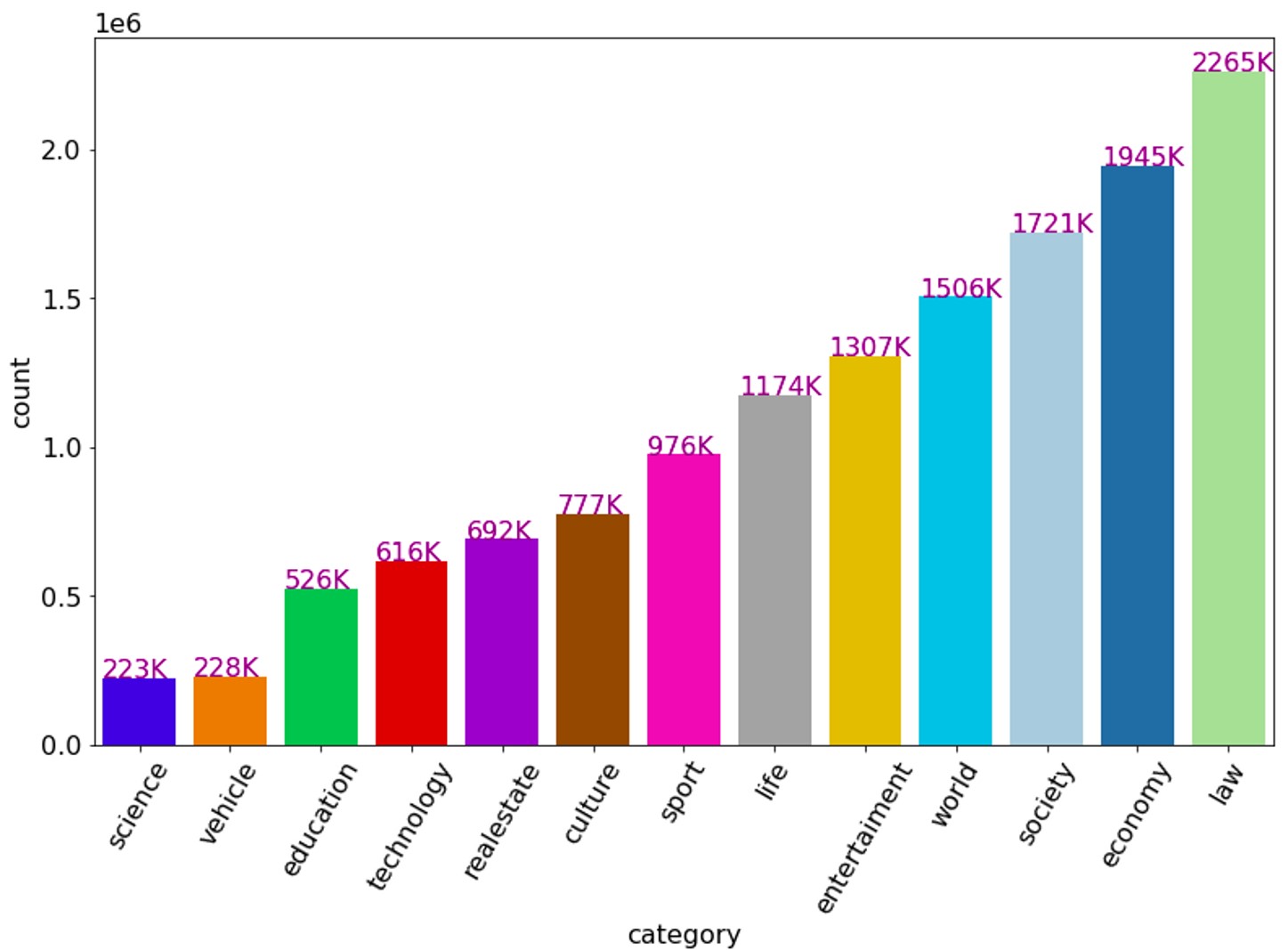
The number of articles belongs to each category
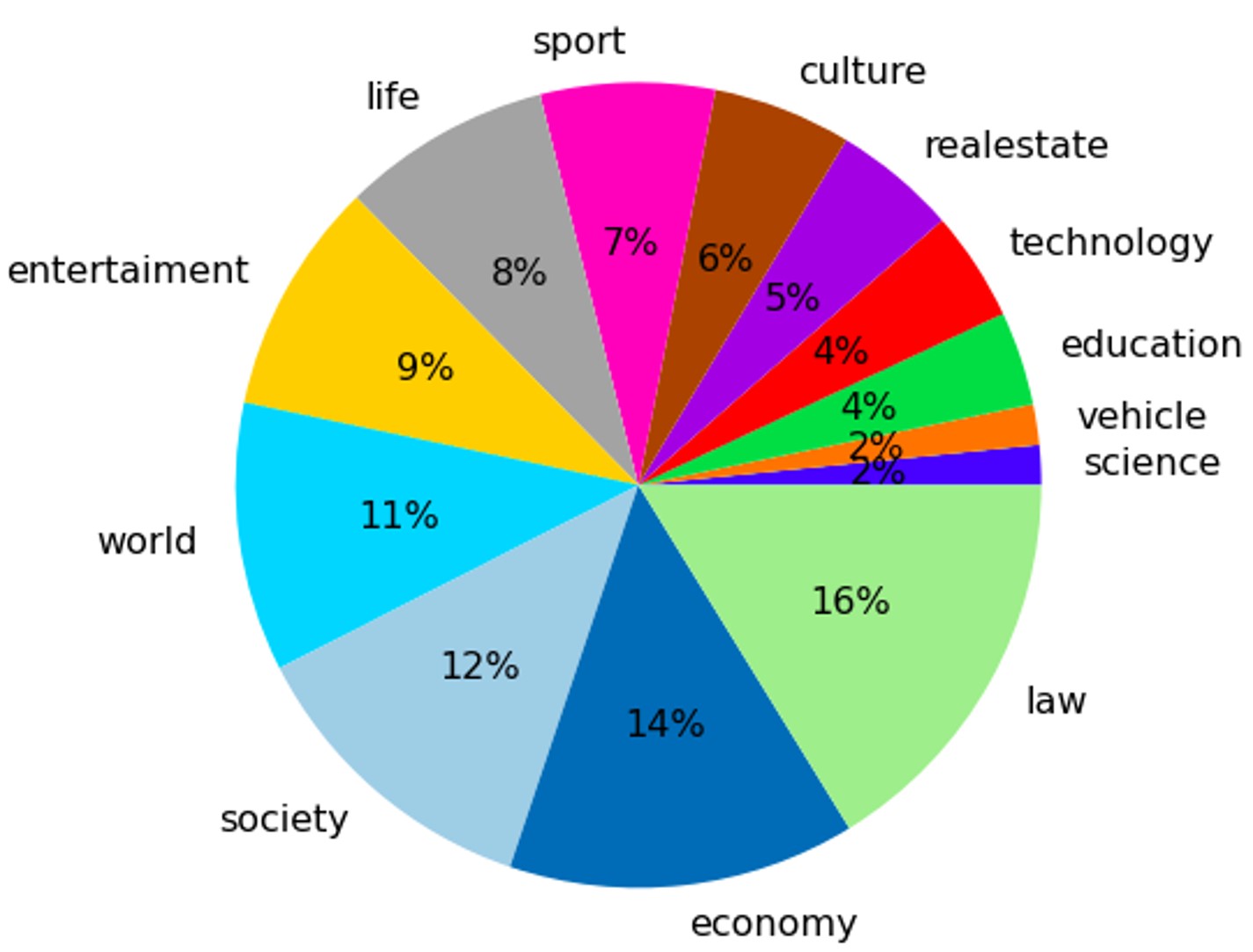
The propotion of articles belongs to each category
As can be seen from the above figures, the number of articles belonging to each category is imbalanced, where the majority of articles are law (16%) and economy (14%). In contrast, science and vehicle account for only 2% (approximately 223K articles). This issue can make the classifier concentrate more on the majority classes even though all classes are equally important. To make data more balance, there are some popular techniques like over-sampling, under-sampling, class reweight, etc. Besides, using massive data for training a machine learning model consumes lots of memory and takes time without significant improvement. Therefore, in our experiment, the data of all classes are under-sampling resulting in the balanced training datasets consisting of 215800 samples from 13 categories.
Baseline Model
As shown in the below figure, the training pipeline has four main components namely data normalization, embedding, model training, and model evaluation. From raw articles, text data (a concatenation of title, description, and content) is normalized and converted into numerical vectors. Those vectors are considered as features of classifiers that are trained, tuned hyperparameters, and evaluated carefully. The best-trained model is utilized to forecast new crawled articles in our recommendation system. In the following parts, we will discuss each process in more detail.

Model training pipeline
♦ Data normalization
Since our text data (the Unicode string) consists of title, description, and content from different sources, it can be written in a variety of Unicode forms. Besides, some texts still have HTML tags or special characters which are meaningless. Therefore, we do several processes to clean text:
- Normalize text to ‘NFC’ form (Normalization Form Canonical Composition)
- Eliminate HTML tags, numbers, and special punctuations (e.g new line characters, single quotes, ...) from text
- Tokenize a text into tokens using our Coccoc tokenizer (e.g gia đình văn hóa → gia_đình văn_hóa)
- Lower text (e.g Hà_Nội → hà_nội)
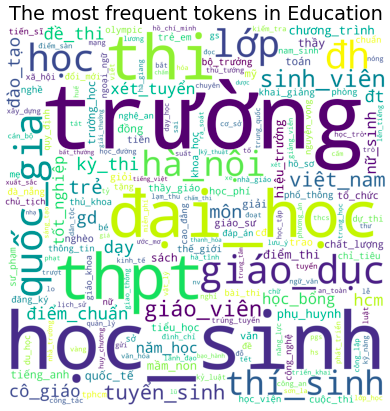
Let’s look at some tokens that are dominant in each category. The most frequent tokens used in Education are ‘học_sinh’, ‘trường’, ‘đại_học’, … compared to ‘hlv’, ‘cup', ‘việt_nam', ‘league' in Sport as shown in the below figures. It indicates that each category has a set of specific tokens describing it. Besides, the size of each token illustrates its frequency or importance.

On the other hand, as there are 13 distinct categories in our dataset, the news categories are encoded into distinct numerical values (classes) as shown in the following block. These labels are independent classes in our multi-class classification problem.
| {'society': 0, |
| 'world': 1, |
| 'culture': 2, |
| 'economy': 3, |
| 'education': 4, |
| 'sport': 5, |
| 'entertainment': 6, |
| 'law': 7, |
| 'technology': 8, |
| 'science': 9, |
| 'life': 10, |
| 'vehicle': 11, |
| 'real estate': 12} |
♦ Word embedding and Document Embedding
Dealing with text data is problematic since our computers, scripts, and machine learning models can’t read and understand text in any human sense. How can we numerically represent textual input most effectively? Ideally, the numerical representation should preserve as much semantic and syntactic information on words as possible. The traditional representation of the input word is a one-hot vector or TFIDF feature. If the corpus has N-words, each text will be converted to an N-dimensional vector. Those representations face some daunting issues like big vocabulary size, sparse vector, no semantic similarity, etc.
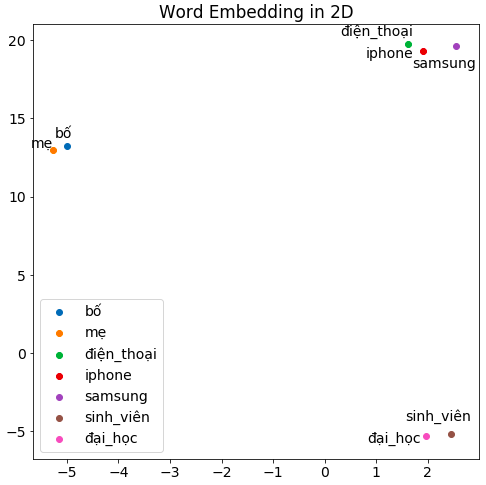
An alternative approach for word representation is utilizing a pre-trained word embedding model. It is said that word embedding is a learned representation for text where words that have the same meaning have a similar representation. Indeed, individual words are represented as real-valued vectors (densely distributed representations) in a predefined vector space (M dimensions). In practice, N is often huge and much larger than M (N>>M). The learning word vector process is either joined with the neural network model on some tasks, such as document classification, or is an unsupervised process, using document statistics. For the news categorization task, we will use Vietnamese Fasttext pre-trained word embedding for obtaining 300-dimensional vector representations for words (M=300). The visualization of word embedding of several words such as 'bố', 'điện_thoại', 'sinh_viên', 'iphone', 'mẹ', 'samsung', 'đại_học' is illustrated in the below figure by mapping 300-D vectors to 2D vectors using UMAP algorithms. As can be seen from the figure, there are three distinct clusters containing words with similar meanings: (‘điện_thoại', ‘iphone', ‘samsung'), (‘bố', ‘mẹ') and (‘sinh_viên, ‘đại_học').
When it comes to using pre-trained embeddings, we have two options:
- Static: where the embedding is kept static and is used as a component of our model. This approach is suitable in case of embedding is a good fit for our problem and releases good results.
- Fine-tune: where the pre-trained embedding is used to initialize the model, but the embedding is updated jointly during the training of the model.
In our task, the pre-trained embedding is used to generate static features for our tree-based model. Then the aggregation from word embeddings like mean or summation is used for document representation (document embeddings) representing document features for training machine learning model.
♦ Training the baseline model
In this experiment, we compare the performance of several classifiers such as Xgboost, Lightgbm, Catboost, etc using the F1-score metric ((F1 = 2×precision×recall / (precision + recall)). These classifiers are trained 5 folds with default parameters using Pycaret. The F1-score of a class is the harmonic mean of precision and recall where the precision of a class defines how trustable is the result when the model answers that an article belongs to that class while the recall of a class expresses how well the model is able to detect that class. Given a class, the different combinations of recall and precision indicate the following meanings:
- high recall and high precision mean that the class is perfectly handled by the model
- low recall and high precision mean that the model can’t detect the class well but is highly trustable when it does
- high recall and low precision mean that the class is well detected but the model also includes samples from other classes in it
- low recall and low precision mean that the class is poorly handled by the model
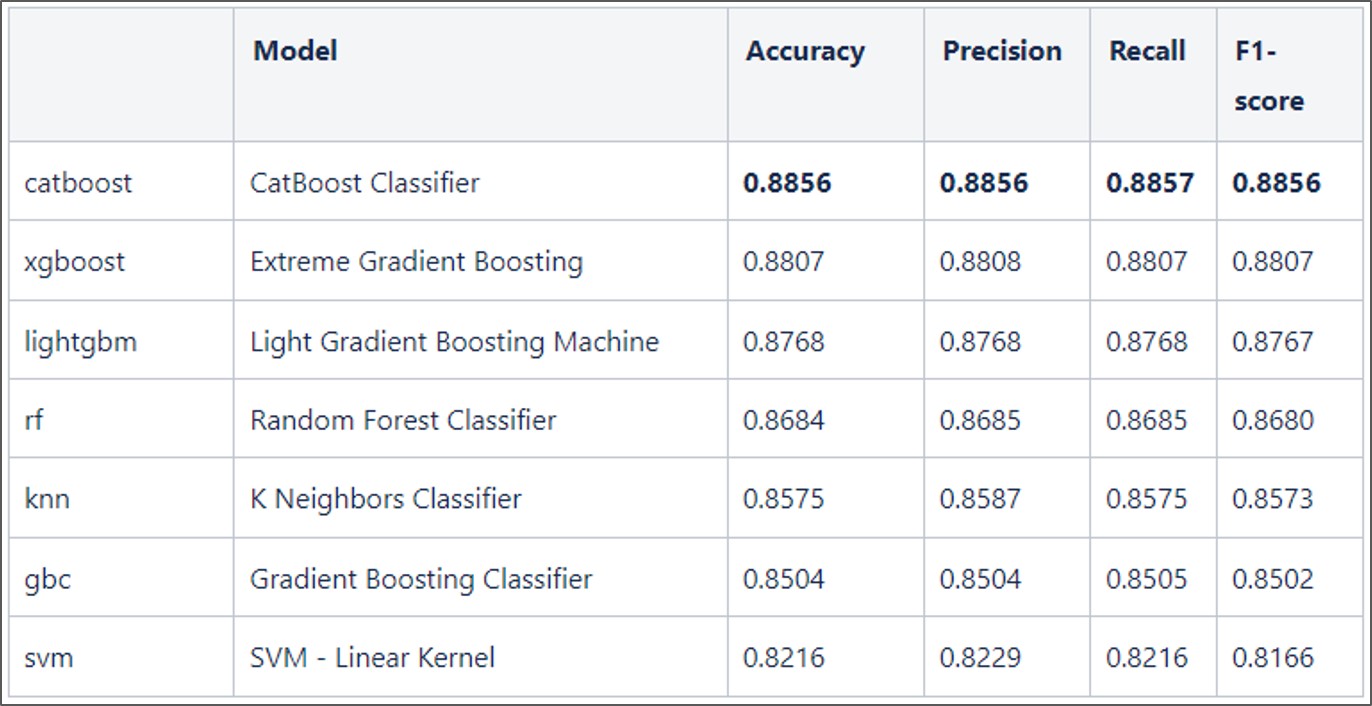
In the following table, obviously, the Catboost classifier achieves the highest overall F1 score (88%) followed by Xgboost and Lightgbm. Meanwhile, other methods (KNN, GBC, and SVM) show worse results (less than 86%). Furthermore, in our experiment, for inference (prediction) time, Catboost also is more effective than other machine learning algorithms.
♦ Evaluation
On the validation dataset accounting for 20% of the training dataset, our Catboost model achieves a high average F1 score (88%). Especially, it can recognize ‘Life’ and ‘Education’ well with 96% and 95% F1-score respectively while ‘Real-estate’ and ‘Technology’ and ‘Society’ are handled poorly, just over 82%.
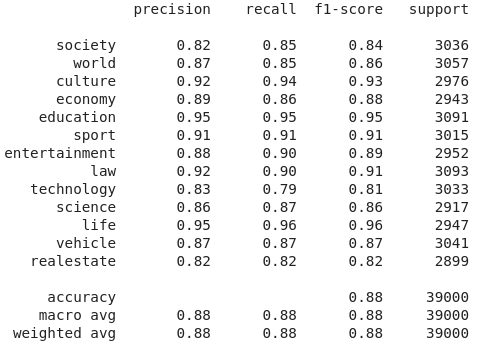
The performance of the baseline model on the validation set
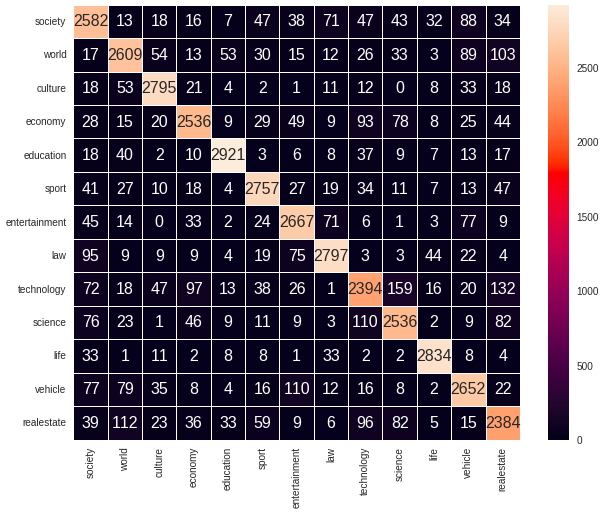
Confusion matrix
Let's look at its confusion matrix where the row describes the ground truth labels and the column shows predicted ones. It provides more insight into not only the performance of a predictive model, but also which categories are being forecasted precisely, which incorrectly, and what type of errors are being made. It is observed that some Technology articles are predicted as Science, Real Estate, or Economy while Real-estate articles are predicted as World News or Technology. Since our model is a multi-class classifier, each article is assigned to the most potential category. Nevertheless, in reality, many articles can belong to more than one class, for example, an article represents the application of technology in education or a football star buying lots of luxury villas. This is a reason causing the relative decline in our model performance.
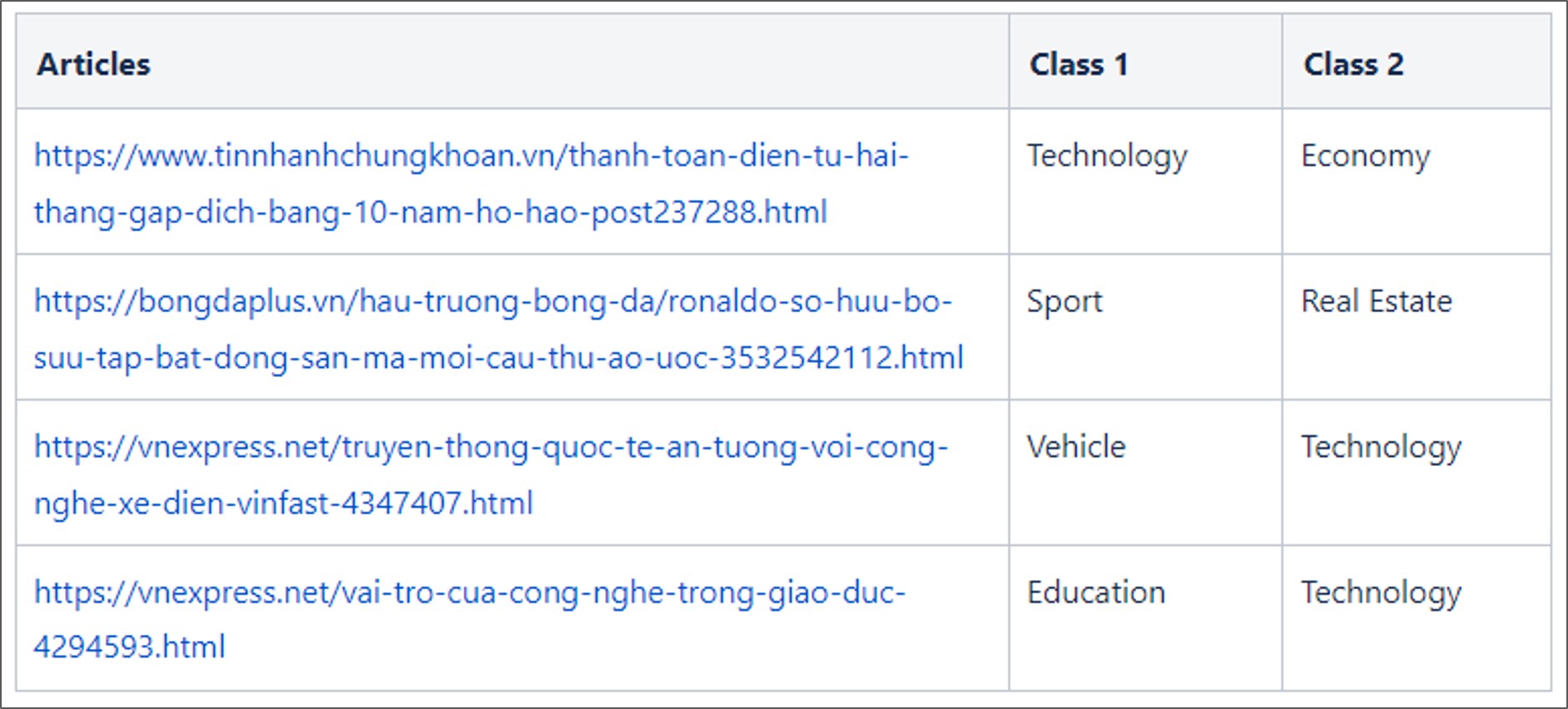
Online prediction

Online prediction pipeline
There are thousands of articles crawled daily from hundreds of websites which then are pushed into Kafka. Then our model on production consumes those messages immediately to classify them into pre-defined categories before storing all metadata on ClickHouse database. This category information is critical to identify user preferences, cluster news, distribute similar articles or do some analysis afterward, etc.
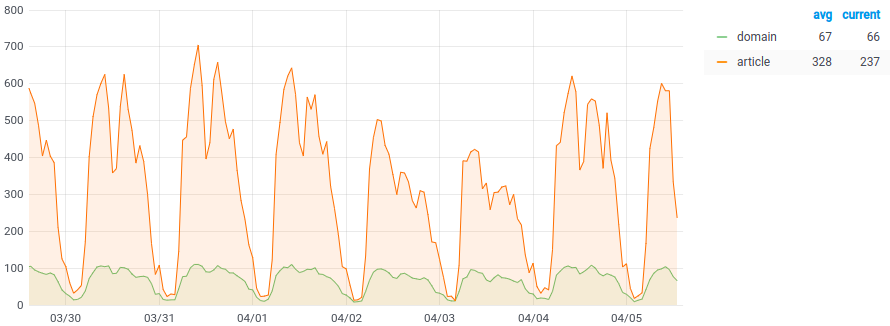
The number of articles is crawled and classified within an hour
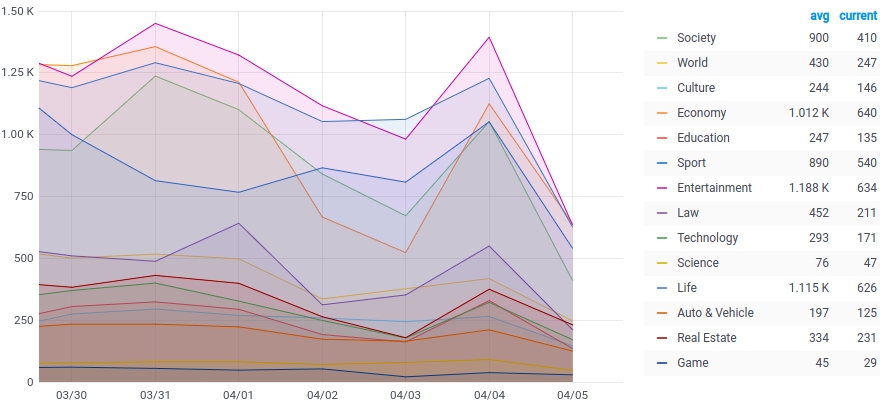
The number of daily articles belongs to each category
Model Upgradation
Although our baseline model shows good performance during the training period, we observe two issues when running it onto production that can make a significant impact on our prediction:
- A bunch of crawled articles is classified incorrectly since they don’t fall into any 13 categories. Looking deeper, we recognize that they are Game news from some websites like 2game.vn, gamek.vn, genk.vn, game4v.com, or so. Those are often predicted as Technology, Entertainment making our Recommender System learn user preferences incorrectly.
- The domain of an URL in some ways brings us informative indicators such as the news from bongdaplus.com are potentially Sport, and ones from 2game.vn are mainly Game.
Therefore, we make a decision that the upgradation of our news categorization model in August 2021 should have one more class Game (14 classes in total) and the domain of an URL is utilized as an additional feature for classifiers. A new training dataset containing nearly 400K news was collected from 03-2021 to 08-2021 in which 25K samples are Game news. The input features for classifiers now are the numerical features from the document embedding (title, description, and content) along with the categorical feature domain.
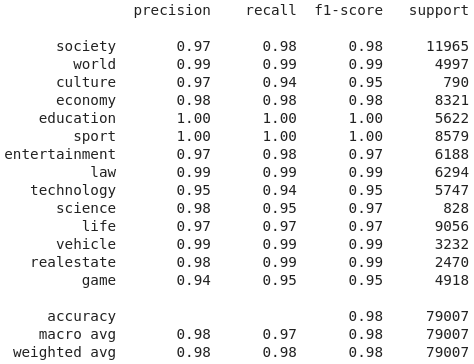
The performance of the upgrade model on the validation set
The performance of the upgrade model shows promising results where the F1-score reaches 0.98 during the training period. In order to have an optimistic evaluation, we take 1487 unseen articles and compare the effectiveness of the two models. Generally speaking, the upgrade model outperforms significantly the baseline model with an 8% weighted average F1-score improvement from 81% to 89%. Some classes such as Culture and Technology witness a soar of 30% and 17% respectively. One noticeable that the baseline model doesn’t have the Game category, so its F1 score is 0 whilst for the upgrade model, it is 0.81.
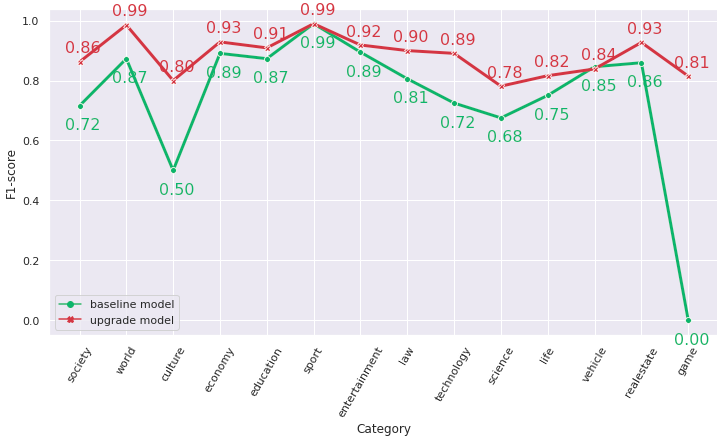
The F1 score of each class of two models on the unseen dataset
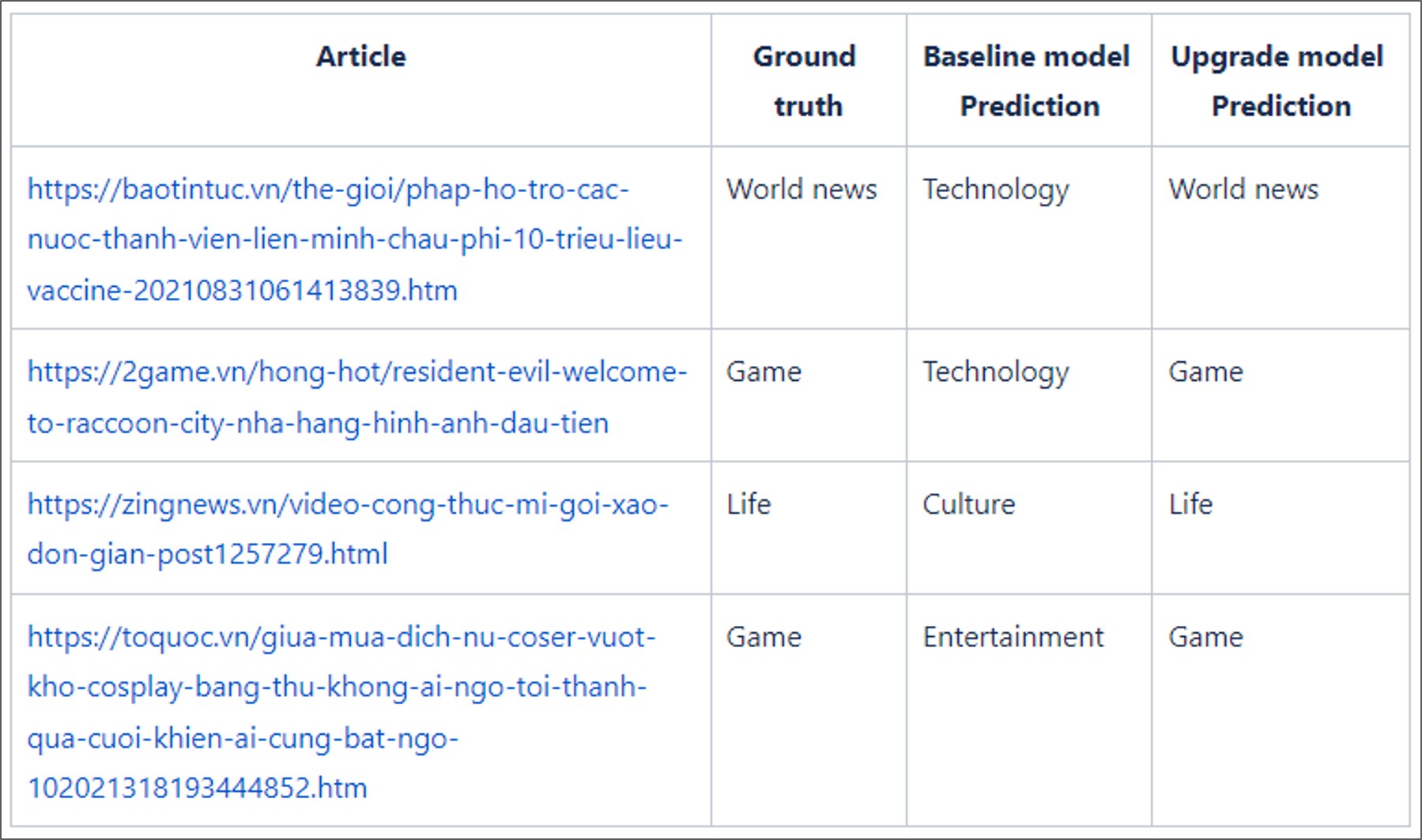
Here are some instances where the upgrade model forecasts a label precisely while the baseline predicts incorrectly.
Conclusions
In this blog, we illustrate some challenges and our solution when building the news classification model which is a critical component of our Newsfeed recommendation system. It not only automatically classifies thousands of articles daily with high accuracy but also helps analyze and distribute the right content to millions of Cốc Cốc users. Nevertheless, we still have room for improvement such as ensemble learning, Bert for word embedding, etc.
References
- https://towardsdatascience.com/handling-imbalanced-datasets-in-machine-learning-7a0e84220f28
- https://machinelearningmastery.com/what-are-word-embeddings/
- https://github.com/catboost/benchmarks/blob/master/model_evaluation_speed/model_evaluation_benchmark.ipynb
- https://neptune.ai/blog/when-to-choose-catboost-over-xgboost-or-lightgbm