

Preface
We’ve heard of Log-Structured Merge-Tree (LSMTree) many times recently, when many high scalable NoSQLs are gaining popularity such as Cassandra, HBase, LevelDB, Elasticsearch… We may have a very brief idea of how they work under the hood theoretically, but we haven’t touched that in depth. We know the engine’s pros and also the cons in comparison with BTree, we learn by heart that “LSMTree is write-preferrable, and BTree vise-versa”, but do we actually understand why it has these characteristics?
In this blog post, we do not guarantee that you’ll understand every aspect of LSMTree DBMS, but we’ll together build a key-value toy database, that follows the idea of the engine. Consequently, we will know a little bit deeper about how it works through the toy we build, from theory to practice. Surprisingly, it’s not that hard as we only read and imagine first-hand!
Log-Structured Merge-Tree
LSMTree is a data structure that allows append-only operations, that’s why it stands by its name, “Log-structured”. The database is simply a very big log containing all the key-value pairs, and all the modifications such as create, update, and delete are treated the same — insert new records into the big log. The design sounds very unintuitive at first look, but it brings to the table a remarkable benefit that no other engines can afford: being append-only means writes will always be sequential, maintaining high throughput, low latency, no disk seek, no write amplification (as in BTree)... Now you have a faint idea of why LSMTree is write-preferable. Let’s go on, a database is not that simple.
Of course, LSMTree is not a silver bullet for everything, its read performance is sometimes horribly slow in comparison with traditional BTree counterparts. To understand why the reading is slow, we need to look at the read path. (which happens when a read query comes)
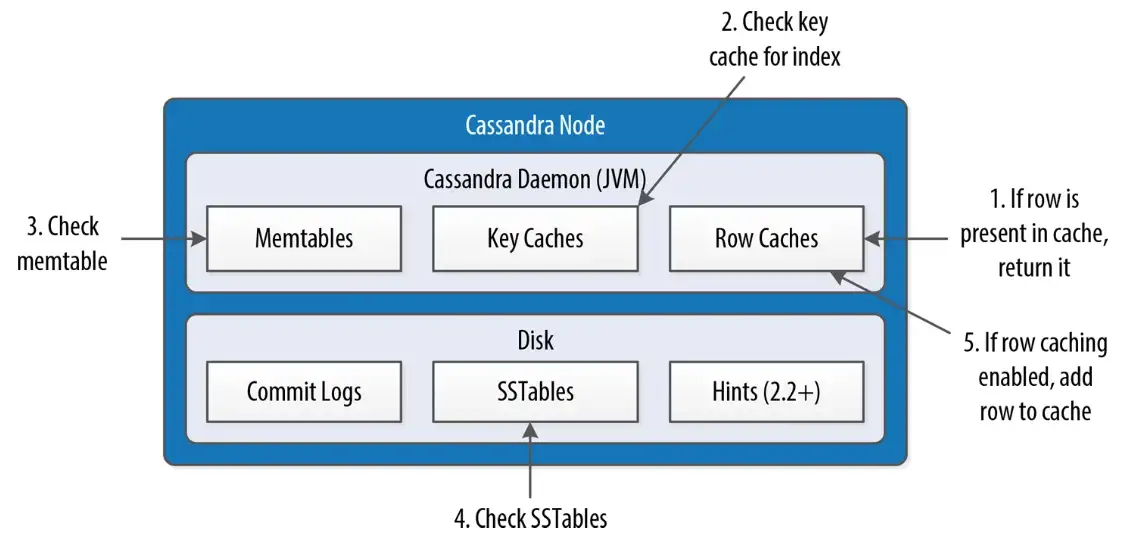
Leaving out all the complications on the diagram above, the write path, which doesn't require disk seeks, is very opposite to the read path, which needs to check data from all the database segments, containing Memtables (the data segments in memory) and SSTables (the data segments on disk). The indexes and caches can help a bit, but eventually, large data need to be scanned because the key can be existed in many places (due to append-only). This is opposite to BTree when the read can find the exact location for a key without scanning all the data.
Understanding Read and Write are crucial for understanding a database, even if it’s just a very surface of a full-featured DBMS. But for the purpose of this blog post, it’s enough for us to get ahead in building our toy. Let’s get our hands dirty.
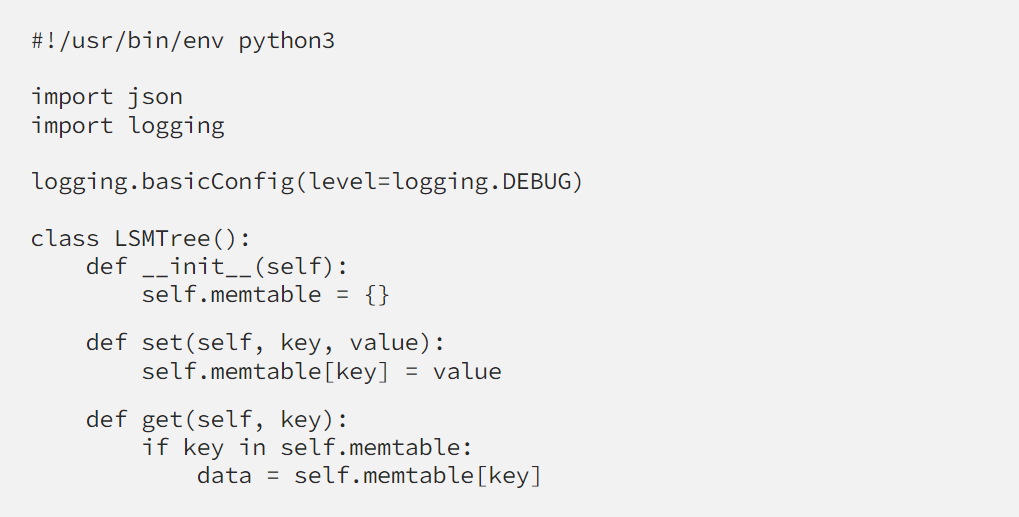
Next, we’ll need a bit of durability, so that our precious data would not be lost when the database shutdown. Function flush() will be called when the database exit, and it has to flush all the data from memtable to disk. The startup() function does the opposite job, reading all the data from the disk and push back to memtable, so we can operate on that in-memory database.
Whenever starting up, the whole DB will be reloaded into our memory, so it’s unusable with a large dataset. Anyway, without an index, there’s nearly impossible to operate without scanning the whole dataset, and implementing an index is out of the scope of this blog post, so we leave it as is. There are not any LSMTree characteristics for now.
Journaling
There’s a problem with the current setup, if the DB is crashed during operations then the data between DB startups will be lost. Nearly all DBMS now are having a mechanism called “journaling” (or commit log) to deal with this kind of loss.
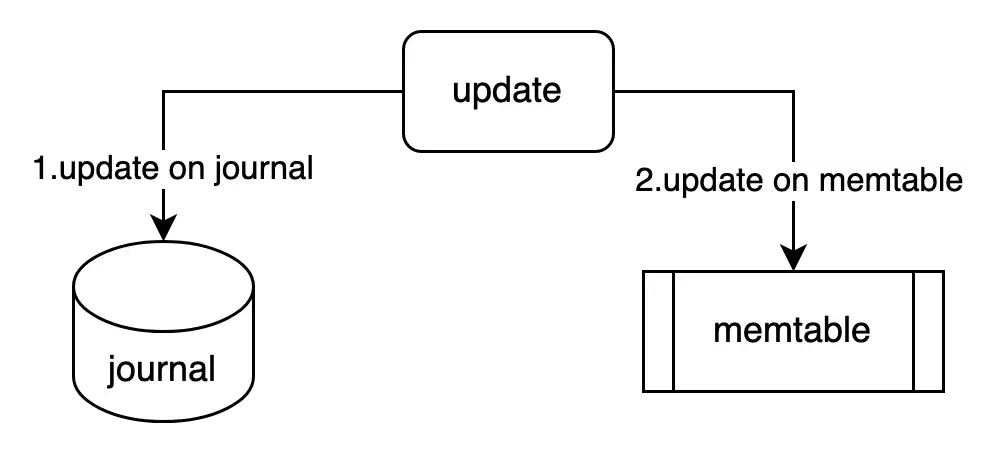
journaling
First, the database after receiving a write query will append that updated info into the journal (which resides on disk), then if it succeeds, the update will be taken place on memtable (on memory, which would be very fast). After step 2, it returns to the client to acknowledge that the write is successful (non-blocking because it doesn't need to wait for disk write). If the crash happens during flushing memtable to disk, the database when starting up can replay the update on the journal to recover lost updates.
Let’s implement a journal for our db
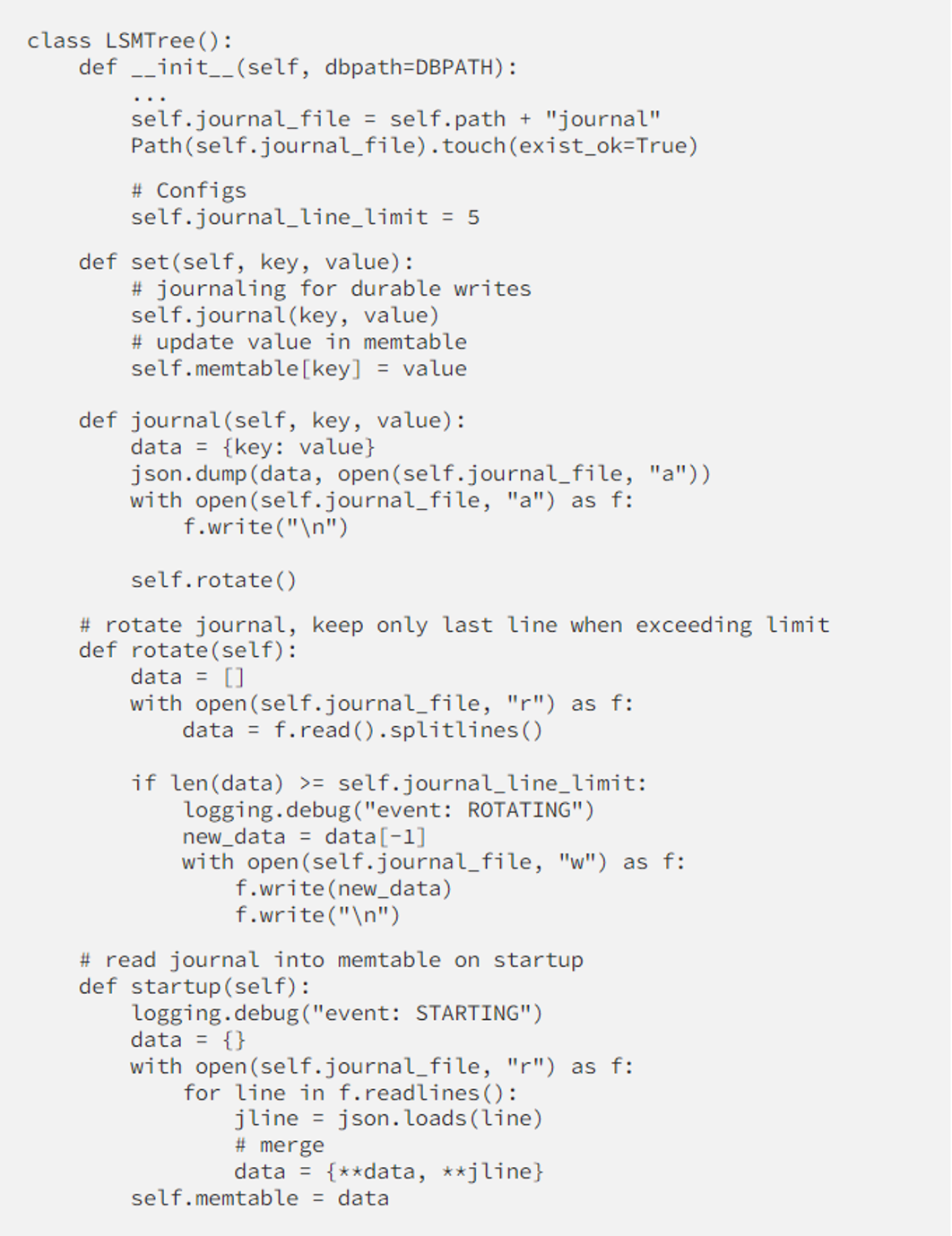
We even implement a cool feature that rotates the journal log when it exceeds a threshold, for not growing too large. Basically, our DB is single-threaded so no need to keep too many records in the journal.
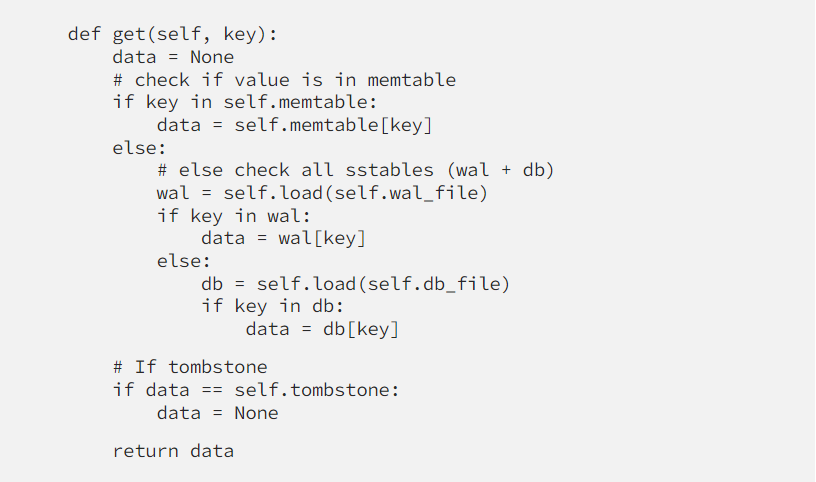
You can notice that for now, we haven’t loaded the whole DB into memtable, only the journal for recovery after a crash, so get() is not working properly at the moment. We’ll implement the idea of LSMTree to operate on part of the dataset instead of a whole, for better performance.
Write-Ahead Log
If our memtable hold too much data while the journal is rotated, a crash can clear all the un-journaled in-memory data. We need to find a way to flush the in-memory dataset into a persistent disk before the journal is cleared out. There’re 2 common approaches employed by databases nowadays:
1. flush the memtable to the persistence file on every update operation. This method slows down the database significantly in tradeoff with consistency.
2. flush the memtable to the persistence file according to its size or how long it hasn’t been flushed, or periodically (determined by space and time). We’ll choose this approach with config memtable_obj_limit = 5
If the memtable is flushed to the main database file db_file, it’ll be very slow because the whole db needs to be reread and rewritten. In LSMTree DB, memtables flush to sstables, then sstables will be merged together to a bigger sstables (Merge-Trees) by other asynchronous threads/processes, so older sstables will be untouched until merges happen (compaction), and main processing threads’ performance won't be affected.
We will inherit this characteristic, by flushing our memtable to a file called Write-Ahead Log (WAL), and after some time, merge wal with the main db file. In official terms, our wal and db files can be considered as 2 separated SSTables. Basically, we can use as many WALs as needed, but for sake of simplicity, we use only one.
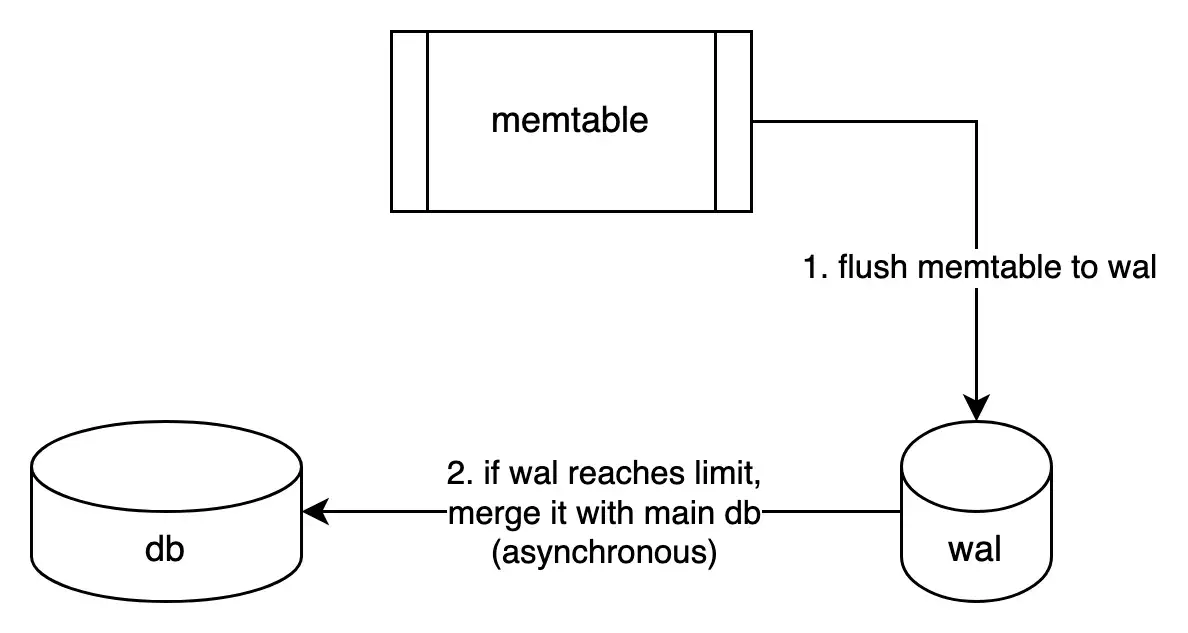
flush process flow
In short, the main advantages of using WAL (or SSTables in Cassandra or alike):
- updates will be appended to persistence, no in-place update
- separate big db files into many small chunks, read can check the latest chunks to get the latest data without scanning all the chunks
Our DB is quite enough with write, let’s get back to read.
Reading in LSMTree
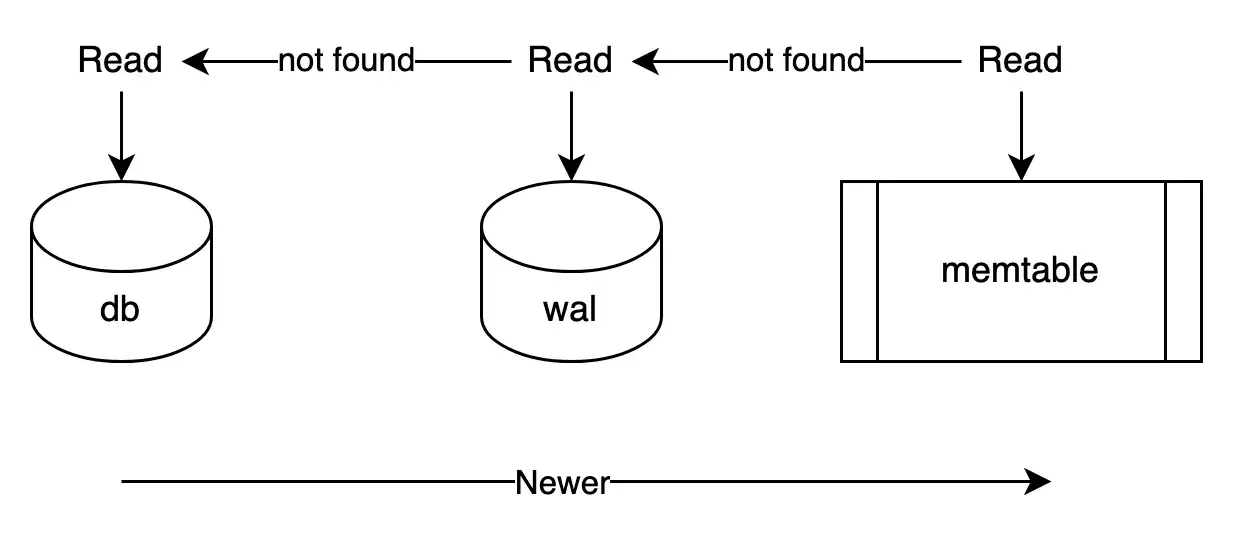
Read path
We’re not having 3 chunks of data: memtable, wal, and db. Memtable contains the latest data, so if we can get what it’s needed from memtable, disk access is not required. The idea applies to all DBMS as can be seen in Bufferpool in MySQL, WiredTiger cache in MongoDB, and so on…
Delete by inserting tombstones
The main problem of LSMTree is deleting is tricky because of no in-place replacement. For deleting we need to seek from all the chunks and delete that key if any. To overcome this issue the database inserts a “tombstone” to the key which is supposed to be deleted (term and mechanism borrowed from Cassandra). For that, the “delete” semantic is still an append-only operation.
As in the read path depicted above, whenever it read the tombstone, the key is considered deleted. It will be truly deleted by merging. (or compaction)
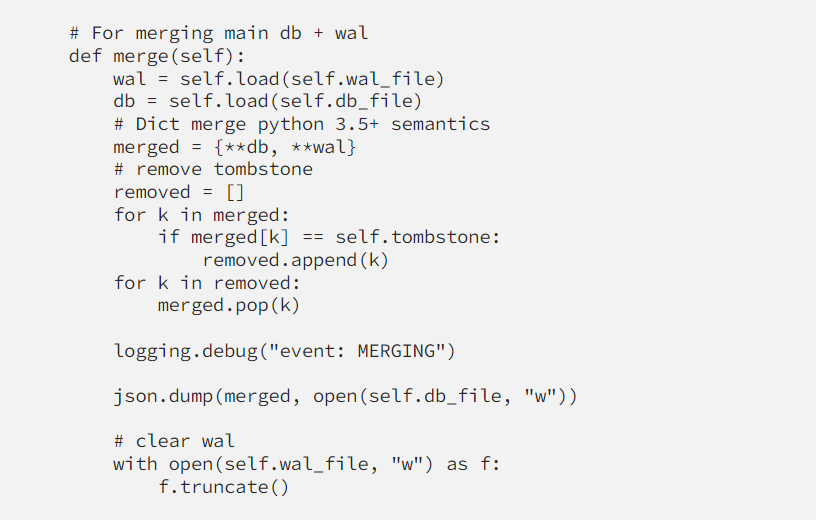
See what a toy can do

As can be seen, key “6” was deleted so its value is “delete_tombstone”, and on the MERGING event, it’s eventually deleted. get("6") returns None even before MERGING as designed.
We’ve completed a very first demonstration on how to build a functioning key-value database. As it’s not nearly applicable in any serious application, the idea of LSMTree is realized and is understandable in just ~100 lines of code, and can be developed even more for new features and better performance. Most of all, the toy opens paths for understanding the LSMTree storage engine in more complex, complicated well-known databases such as Cassandra, Elasticsearch… which is the main purpose of this demonstration.
References
- https://github.com/wintdw/python-lsmtdb
- https://dev.to/creativcoder/what-is-a-lsm-tree-3d75
- Cassandra The Definitive Guide (3rd Edition) — Chapter 9: Reading and Writing Data