
1. Introduction
When it comes to memory usage, there are (typically) two types of programs. The first type is programs that allocate memory in large blocks. Usually, they know precisely how much memory they will need and can allocate it in advance. Think about it like you are creating a monolith of memory with fixed size and use this resource in your entire program lifetime, no less. These programs hold their memory in arrays or vectors and typically access it linearly (but only sometimes so). These programs might even use dynamic memory, but when they do, they commonly call malloc only a few times during the program’s lifetime. In other words, memory allocation and memory organization are not typically limiting factors in these programs.
The second type of program, and more popular for us, uses memory differently. The programs do not know how many resources they will need (e.g. for scalability or security), so they might use data structures or message passing that require allocating many memory chunks using malloc or new (C++). Thus, the program allocates many memory chunks (typically small), uses them for some time, and then returns them to the system.
Of course, programs need to spend time on memory allocation. However, if this time is too big, you can sense a performance bottleneck issue that you should investigate if the performance is crucial.
Please note that there are two things to consider when talking about the performance of dynamic memory usage:
- memory allocation speed: This depends mostly on how good the implementations of malloc or free (new and delete in C++) are.
- allocator access speed: Access speed depends on hardware memory subsystems, and some system allocators are better at allocating memory in a way that benefits hardware memory subsystems.
In this post, I will talk about allocation speed, the big picture for why memory allocation and deallocation are slow, and suggest a (comprehensive) technique list on how to speed up critical places. The access speed will be the topic of a follow-up post.
2. Drawbacks of malloc and free design
Because malloc and free are parts of ISO C, C/C++ compiler vendors have implemented them based on The C Standard Library guideline. Undoubtedly, these functions meet all the requirements for general purposes. However, when talking about performance-critical software, they are usually the first thing you want to replace.
2.1. Memory fragmentation
For most scenes, the allocator demands large blocks of memory from the OS. From such blocks, the allocator splits out into smaller chunks to serve the requests made by programs. There are many approaches to managing these chunks out of a large block. Each algorithm differs in speed (will the allocation be fast) and memory usage.
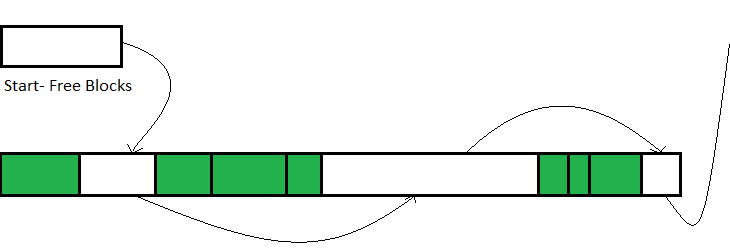
Given the already-allocated green chunks. When the allocator needs to allocate a new chunk, it traverses the list from Free Blocks Start. For speed optimization, the allocator can return the first chunk of the appropriate size (first-fit algorithm). For memory consumption, the allocator can return the chunk whose size most closely matches the requested size by the calling code (best-fit algorithm).
So The allocator itself still needs an algorithm and takes time to find an appropriate block of a given size. Moreover, it gets harder to find the block over time. The reason for this is called memory fragmentation.
Given the following scenario, the heap consists of 5 chunks. The program allocates all of them, and after a time, it returns chunks 1, 3, and 4.

Memory Fragmentation Illustration. Each block is 16 bytes in size. Green blocks are marked as allocated, and red blocks are available.
When the program requests a chunk of size 32 bytes (2 consecutive 16-byte chunks), the allocator would need to traverse to find the block of that size since it is available at 3 and 4. If the program wants to allocate a block of size 48 bytes, the allocator will fail because it cannot find a subset of contiguous chunks, although there are 48 bytes available in the large block (blocks 1, 3, and 4).
Therefore, you can now imagine that as time passes, the malloc and free functions get slower because the block of the appropriate size is more challenging to find. Moreover, suppose your program wants to allocate a larger block. In that case, the allocation might fail because a continuous chunk with the requested size is unavailable (even though there is enough memory in total).
Memory fragmentation is a severe problem for long-running systems. It causes programs to become slower or run out of memory. Think about that you have a TV Box. You change a channel every 5 seconds for 48 hours. In the beginning, it took 1 second for the video to start running after changing the channel. Then after 48 hours, it took 7 seconds to do the same. It is memory fragmentation.
2.2. Thread Synchronization
For multi-threaded programs (typical for nowadays), malloc and free are required to be thread-safe by default. The simplest way that C/C++ library vendor can implement them thread-safe is to introduce mutexes to protect the critical section of those functions, but this comes with a cost. Lock and unlock mutexes are expensive operations on multi-processor systems. Synchronization can waste the speed advantage, even how quickly the allocator can find a memory block of appropriate size.
Several allocators have guaranteed the performance in multi-threaded/multi-processor systems to resolve this issue. In general, the main idea is to make it synchronization-free if the memory block is exactly accessed from a single thread (e.g. reserving per-thread memory or maintaining per-thread cache for recently used memory chunks).
The above strategy works well for most of the use cases. However, the runtime performance can be awful when the program allocates and deallocates memory in different threads (worst-case). Moreover, this strategy generally increases program memory usage.
3. Program slowness caused by allocators
In overview, there are three main reasons which come from allocators that slow down the program:
-
Huge demands on the allocator: requesting to allocate/deallocate a large number of memory chunks (malloc and free) will limit the program performance.
-
Memory fragmentation: the more fragmented memory is, the slower malloc and free are.
-
Ineffective allocator implementation: allocators by C/C++ Standard Library are for general purposes, so they are not ideal for performance-critical programs.
Resolving any of the above causes should make your program faster (in principle). Moreover, please note that these mentioned reasons are not entirely independent of each other. For example, reducing memory fragmentation can also be fixed by decreasing the pressure on the allocator.
4. Optimization Strategies
The following sections present notable techniques to reduce the program’s dynamic memory consumption, to fasten its runtime performance.
Please note that Pre-mature optimization is the root of all evil. Know your domain and profile, and benchmark your program to find the slowness root cause. These sections are the suggestions for “fine-tuning” the applications. They do not provide or propose techniques to rewrite the program more efficiently.
4.1. Contiguous containers of pointers
In C++, polymorphism can be achieved by using vectors of pointers (e.g., vector<T*> or vector<unique_ptr<T>>). However, this solution puts huge pressure on the system allocator: creating/releasing an element(pointer) in the vector results in a call to new (malloc).
Large vector(s) of pointers will lead to degradation in speed performance as the data set grows because of the demand pressure on the allocator and memory fragmentation.
An approach for this issue is using a pointer of a vector of objects (e.g., vector<T>* or unique_ptr<vector<T>>). This usage ensures all the elements in a continuous block, improves data locality (I will talk about data locality in the next post), and drastically decreases the number of calls to the system allocator.
However, this solution can only work for a single type. If you need polymorphism, there are several polymorphism libraries that you can search for. Personally, I will choose the implementation from Microsoft.
4.2. Custom STL Allocator
STL data structures like trees (e.g. set and map), hash maps (e.g. unordered_set and unordered_map), and vectors of pointers make a large number of requests for memory chunks from the allocator, increase memory fragmentation, as a consequence, decrease the performance.
Fortunately, STL data structures accept a user-specified Allocator as one of the template arguments.
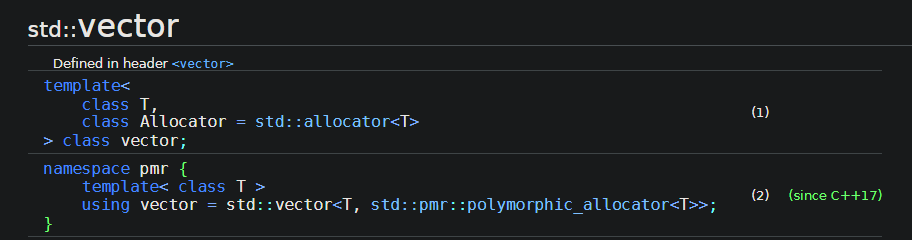
Template interface of std::vector. Issued on 01/02/2023.
STL data structures call special methods allocate to request memory and deallocate to release the unneeded memory from the Allocator. Users can specify their own Allocator (by implementing these functions and satisfying the STL Allocator requirements) for their own needs.
4.2.1. STL Allocators - Per-Type Allocator
Given std::allocator and CustomStatelessAllocator are stateless allocators, CustomStatefulAllocator is a stateful allocator. Consider the information:

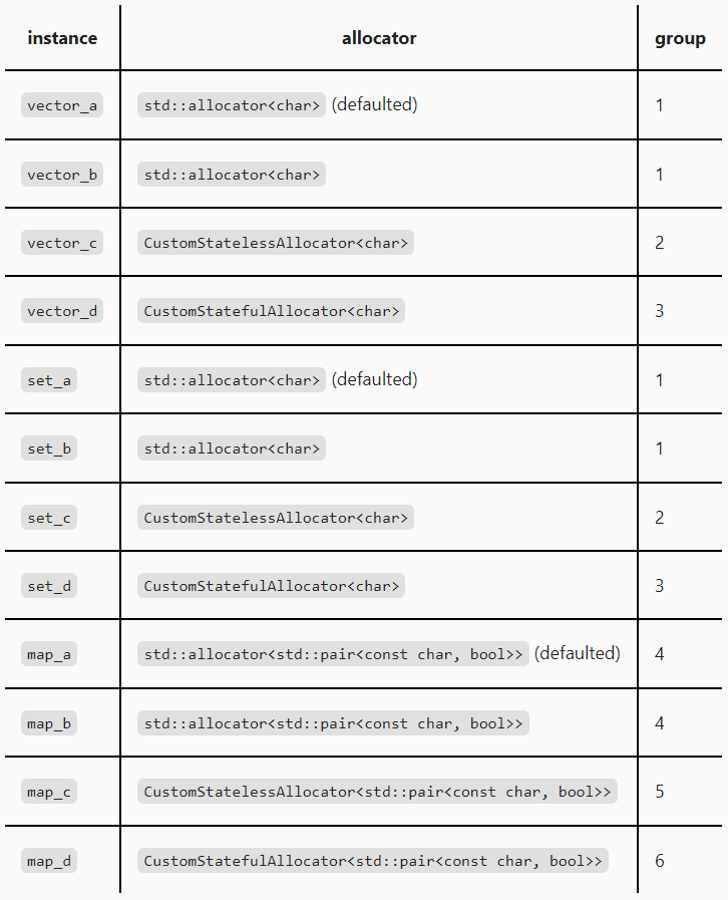
According to cppreference, issued on 01/02/2023:
Every
Allocatortype is either stateful or stateless. Generally, a stateful allocator type can have unequal values which denote distinct memory resources, while a stateless allocator type denotes a single memory resource.
std::allocator per-type allocators: all the data structures of the same type share one instance of the allocator.
4.2.1.1. Design Overview
In a regular allocator, memory chunks belonging to different data structures may end up next to one another in the memory. With an STL allocator, data from different domains are guaranteed in separate memory blocks. This design leads to several improvements:
Decreases memory fragmentation, and increases data locality and access speed since data from the same data structure is in the same memory block:
- STL allocator guarantees that memory chunks are returned to the allocator when the data structure is destroyed. Additionally, when all data structures of the same type are destroyed, the STL allocator returns the free memory to the system.
- Consecutive calls to allocate (deallocate) guarantee to return neighboring chunks in memory
Simple implementation opens up speed opportunities:
- The allocator returns only chunks of a (or multiple of) constant size: memory-fragmentation-free. Any free element will be a perfect fit for any request. Also, since the size is already known (constant size), there is no need for chunk metadata that keeps the information about the chunk’s size.
- no thread-safe requirements unless the data structure is allocated from several threads.
4.2.1.2. Example of customizing STL allocator
Arena Allocator (also called bump allocator) is commonly used for data structures that have little changes after their creation. Since deallocation is a no-op, destruction can be significantly fast.
This section provides a naive Arena Allocator implementation for std::map.
Given the definition of std::map, issued in 01/02/2023:
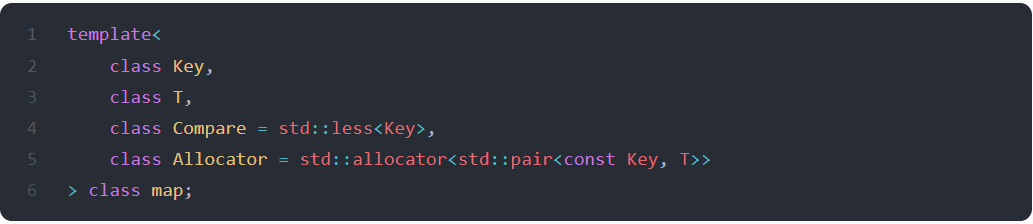
There is a template parameter named Allocator, and it defaults to std::allocator (line 5). If you want to replace the allocator of std::map, you will need to write a class with a few methods that can serve as the replacement for the std::allocator.
Suppose you are using std::map to look up considerable elements, and then you destroy it as soon as afterward. You can provide a custom allocator that allocates from one specific block. Follow the below example:
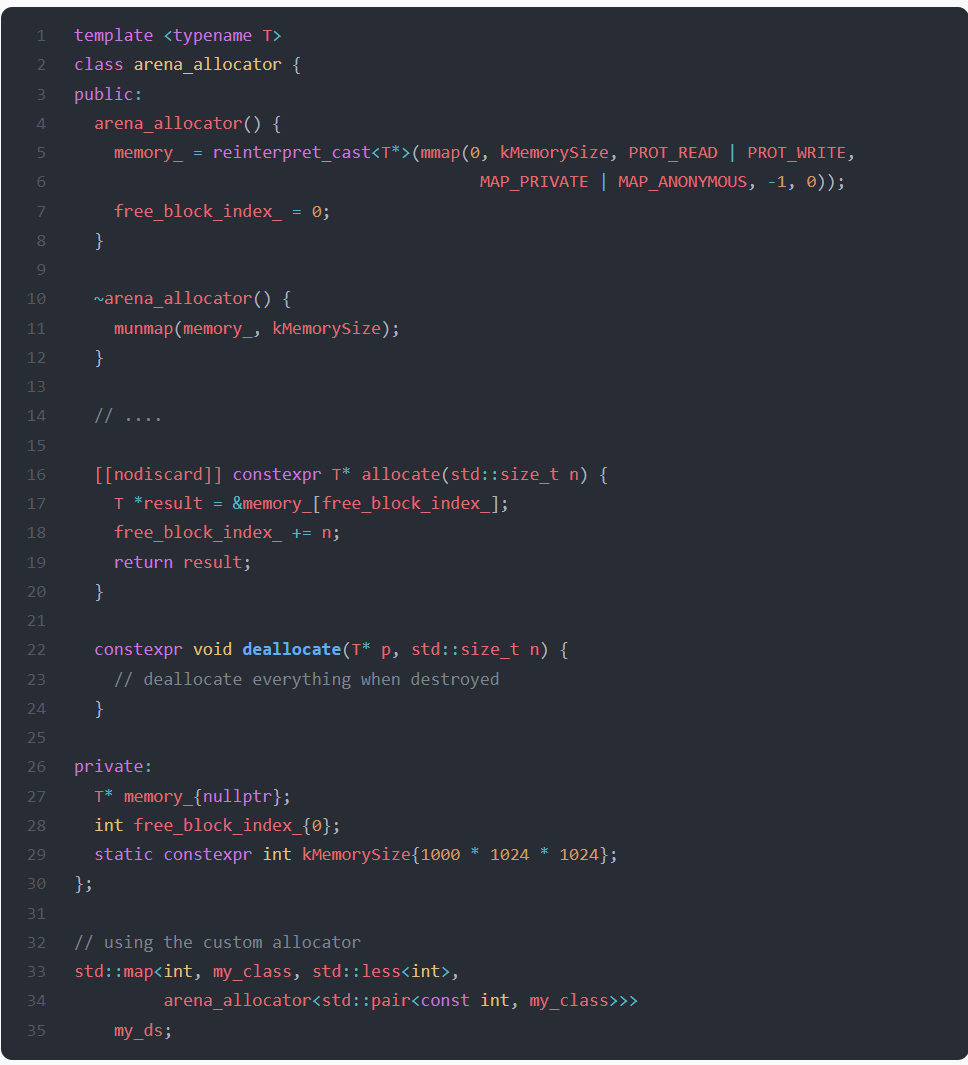
In the above example, on line 5, call mmap to allocate a large block of memory from the OS (it will not allocate all that RAM unless the program uses it). When the arena_allocator instance is destroyed (line 11), the block will get returned to the system. Method allocate returns the first available chunk (lines 17 – 19) in the block, and method deallocate does not do anything. Allocate is fast, and deallocate is a no-op.
This approach will be ideal for the scene where we are allocating a complete std::map at the beginning and then do not do any removal operations. The tree (std::map is usually implemented as a red-black tree) will be compact in memory, which is good for the cache-hit rate and performance. It will make no memory fragmentation since the whole block is separated from other memory blocks.
When removing elements from std::map, even though std::map would call deallocate, no memory would be released. The program’s memory consumption would go up. If this is the case, we would want to implement the deallocate method, but allocation would also need to become more complex.
4.2.2. Per-Instance Allocator
Per-Instance Allocator is ideal when you have several large data structures of the same type. By using a per-instance allocator, the memory needed for a particular data structure instance will be allocated from a dedicated block instead of separating memory blocks per domain (allocating memory pool for each type).
Take an example of a class student which is kept in a std::map<student_id_t, student>, given having two instances, one for the undergraduate students and the other for graduate students. With standard STL allocators, both hash maps share the same allocator. With a per-instance allocator, when destroying an instance, the whole memory block used for that instance is empty and can be directly returned to the OS. This benefits memory fragmentation reduction and data locality increment (faster map traversal).
Unfortunately, STL data structures do not support per-instance allocators, so in this case, you would need to write your data structure with per-instance allocators support.
4.2.3. Tuning the custom allocator
A custom allocator can be adjusted to a specific environment for maximum performance. Knowing your domain will help to pick the right strategy for your custom allocator. The following approaches can be taken into account:
- Static allocator: Preloading with enough space to store elements can be perfectly fit for small data structures. If the context requires extra memory, the allocator can request it from the system allocator. This approach can substantially decrease the number of calls to the system allocator.
- Arena allocator: Only release memory when the allocator is destroyed. It is useful for large data structures that are mostly static after creation.
- Cache allocator: When deallocating, keep certain chunks in the cache instead of returning the whole memory to the system allocator for future usage of allocating requests. Despite not decreasing memory fragmentation, this approach can slow down fragmenting progression.
4.3. Memory chunk caching for producer-consumer
Given a producer thread allocates an object and sends it to the consumer thread. After processing, the consumer thread destroys the object and releases the memory back to the OS. This context puts a large pressure on the system allocator. One approach is to allocate all the objects from a dedicated memory pool using a custom allocator.
In C++, you could overload the operator new/delete to use the new allocator. However, since the object memory lifetime is controlled in separate threads, you must be aware of synchronization. One idea is to use a memory cache on both the allocation and deallocation places. Consider the following source code:
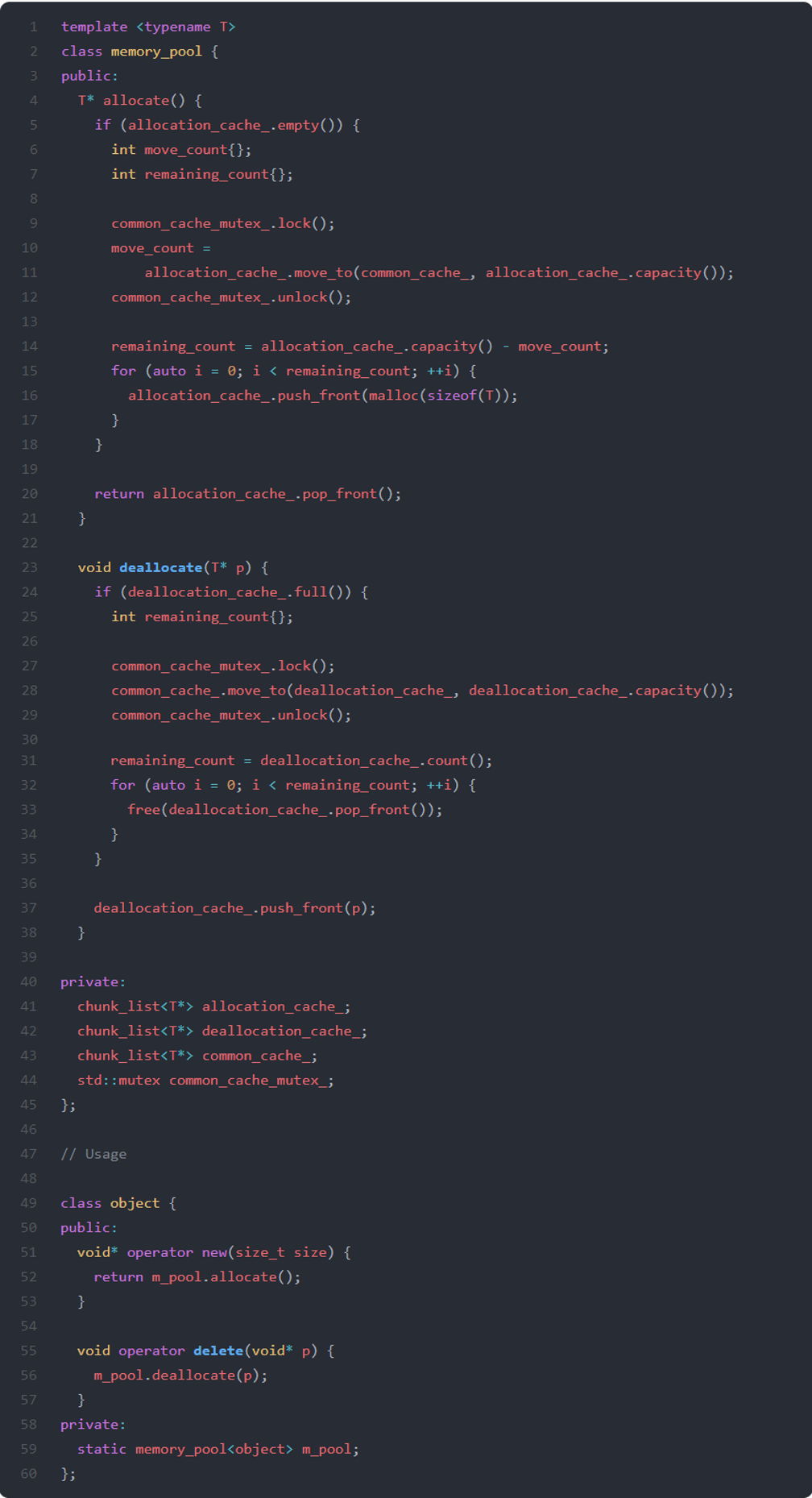
Inside the custom allocator memory_pool are three linked lists containing the cached memory chunks: allocation_cache_, common_cache_, and deallocation_cache_.
When deallocate is called, the memory chunk is not released back to the system allocator. Instead, it is cached (line 37).
- If deallocation_cache_ is full, memory chunks from it are moved to common_cache_(line 28). When the common_cache_ becomes full, the remaining memory chunks are released back to the system allocator (lines 32-34). deallocation_cache_ is empty after this operation.
- Access to common_cache_ has to be secured with a mutex (lines 27 and 29).
- Access to deallocation_cache_ is the common case, we only need to access common_cache_ when deallocation_cache_ is full.
When allocate is called, if available, a memory chunk is taken from the cache (line 20).
- If allocation_cache_ is empty, then additional memory chunks are taken from the common_cache_(line 10). The memory_pool will move chunks (as much as possible) from the common_cache_ to the allocation_cache_ until allocation_cache_ is full.
- If the allocation_cache_ is not full after this operation, the system allocator will request additional memory chunks (lines 15 – 17).
- Access to common_cache_ has to be secured with a mutex (lines 9 and 12).
- Access to allocation_cache_ is the common case, we only need to access common_cache_ when allocation_cache_ is empty.
This solution works only with two threads, one allocates, and the other deallocate objects.
For optimally, the size of allocation_cache_, deallocation_cache_ and common_cache_ need to be chosen carefully:
- Small values make the memory_pool work more with the system allocator than the cached chunk lists.
- A large value makes the memory_pool consume more memory.
- An ideal size for common_cache_ is 2 times bigger than the capacity of the others.
4.4. Small Size Optimizations
Given the class small_vector for storing integers, after profiling, you see that in most of the runtime cases, these objects have small sizes of up to 4. Consider the following (naive) implementation:

We could pre-allocate 4 integers, thus, totally reducing calls to the system allocator.

If we create small_vector with a capacity less than or equal to kPreAllocatedSize (lines 6-7), we use the pre_allocated_storage_. Otherwise, we call the system allocator as usual (lines 9-10).
However, the drawback is the class size increment. On a 64-bit system, the original was 24 bytes, while the new is 40 bytes.
A common solution is using C unions to overlay the data for the pre-allocated case and the heap-allocated case. The most significant bit in size_ can be used for authorization between these cases (0 for pre-allocated and 1 for heap-allocated).
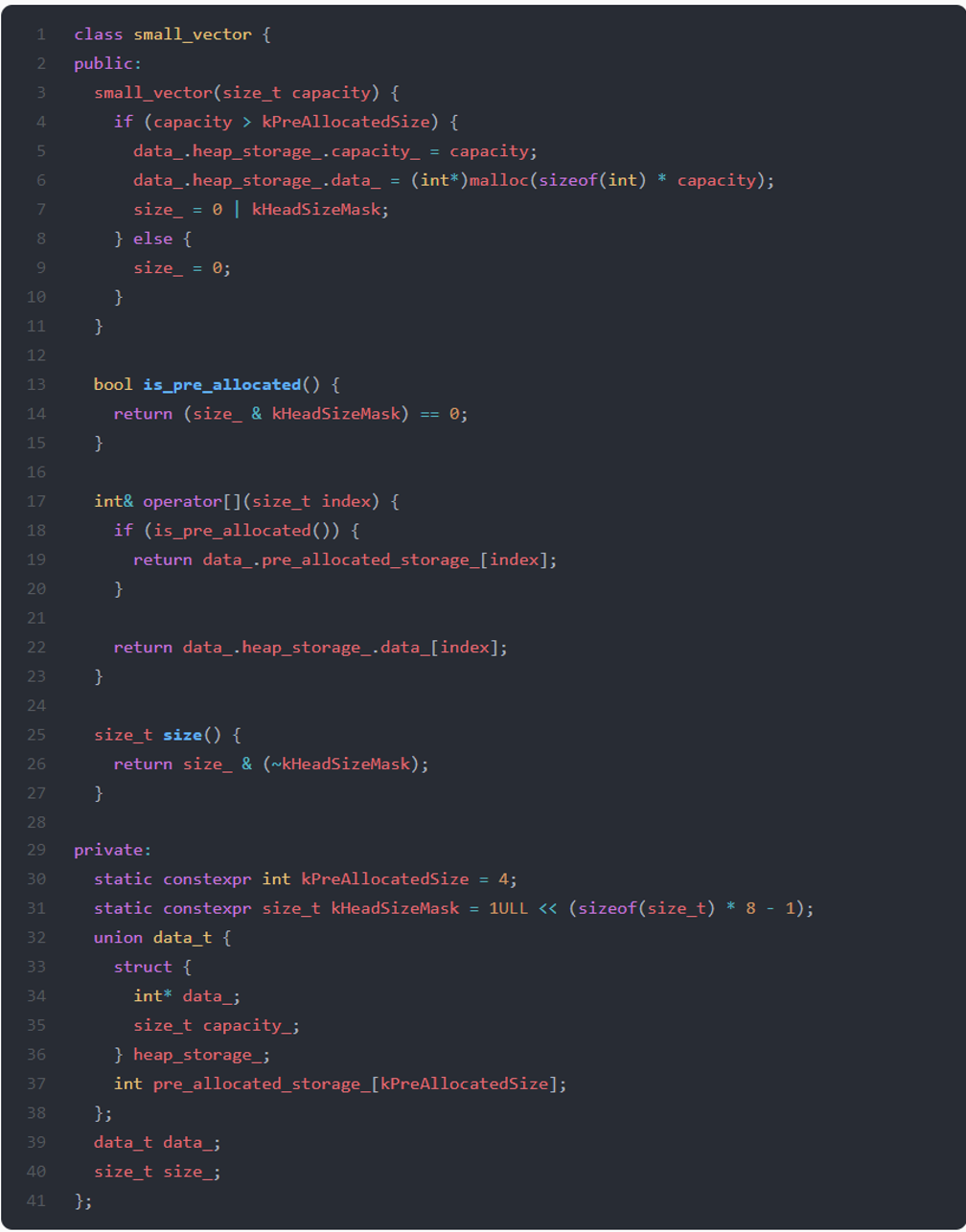
This approach is used in several places. For example, libc++ std::string implementation.
4.5. Fighting memory fragmentation
It is always challenging to reduce memory fragmentation or make it never happens. Sometimes, it is caused by the system, and we cannot do anything. There are a few approaches that can help in these situations:
- Restart: some systems will occasionally restart to avoid memory fragmentation. However, creating a restartable or state-restorable program or system can be challenging.
- Preallocate memory upfront: Some programs pre-allocate all the needed memory at the start and then completely dispense with dynamic memory allocation. MISRA coding guidelines even forbids the usage of dynamic memory in the automotive industry:
MISRA C++ 2008, 18-4-1 - Dynamic heap memory allocation shall not be used.
MISRA C:2004, 20.4 - Dynamic heap memory allocation shall not be used.
MISRA C:2012, 21.3 The memory allocation and deallocation functions of <stdlib.h> shall not be used
However, these guidelines are impossible for programs in other industries where the needed memory is unknown at the beginning of the program.
- Changing the system allocator: several system allocators can be used instead of the built-in one and which promise faster allocation speed, better memory usage, less fragmentation, or better data locality.
5. System Allocators
This section writes about a solution to speed up your program: using a better system allocator for your needs. Several open-source allocators try to achieve efficient allocation and deallocation. However, at the time of writing and personal observation, there has yet to be any allocator who has taken the holy grail.
Regularly, there are four perspectives that each allocator compromises on:
- Allocation Speed: Note that both the speed of malloc and free (new and delete) are important.
- Memory Consumption: Percentage of wasted memory after allocating. The allocator needs to keep some accounting info for each block, which normally takes up some space. Additionally, if the allocator optimizes for allocation speed, it can leave some memory unused.
- Memory Fragmentation: Some allocators have these issues than others, which can affect the speed of long-running applications.
- Cache/Data Locality: Allocators which pack data in smaller blocks and avoid memory losses have better cache/data locality (I will talk about this in a follow-up article)
5.1. Allocators on Linux
When using malloc and free (new and delete) in your program, normally, the C standard library implements those functions. Its allocator is called GNU Allocator, based on ptmalloc. Apart from it, there are several other open-source allocators commonly used on Linux: tcmalloc (by Google), jemalloc (by Facebook), mimalloc (by Microsoft), hoard allocator and ptmalloc.
GNU Allocator is not among the most efficient allocators. However, it does have one advantage, the worst-case runtime and memory usage will be all right.
Other allocators claim to be better in speed, memory usage, or cache/data locality. Before choosing a new system allocator, consider thinking about the following questions:
- Single-thread or multi-threaded?
- Maximum allocation speed or minimum memory consumption? What is the trade-off that you are willing to take?
- Allocator for the whole program or only for the most critical parts?
In Linux, after installing the allocator, you can use an environment variable LD_PRELOAD to replace the default allocator with a custom one:

5.2. The Performance Test
Real-world programs differ too much from one another. Therefore, in this article’s scope, I cannot provide a comprehensive benchmark for allocator performance. An allocator performing well under one load might have different behavior under another.
I suggest you visit Testing Memory Allocators: ptmalloc2 vs tcmalloc vs hoard vs jemalloc While Trying to Simulate Real-World Loads. The author has compared several allocators on a test load that tries to simulate a real-world load. According to the author’s conclusion:
| allocators are similar, and testing your particular application is more important than relying on synthetic benchmarks.
5.3. Notes on using allocators in your program
All the allocators can be fine-tuned to run better on a particular system, but the default configuration should be enough for most use cases. Fine-tuning can be done through environment variables, configuration files, or compilation options.
Normally the allocators provide implementations for malloc and free and will replace the functions with the same name provided by the Standard C library. This design means that your program’s dynamic allocation goes through the new allocator.
However, it is possible to keep default malloc and free implementations together with custom implementations provided by your chosen allocator. Allocators can provide prefixed versions of malloc and free for this purpose (e.g., jemalloc with the prefix je_). In this case, malloc and free will be left unchanged, and you can use je_malloc and je_free to allocate memory only for some parts of your program through jemalloc.
6. Final Words
This article represented several optimization solutions for how to allocate memory faster.
Ready-made allocators have the benefit of being very easy to set up, and you can see the improvements within minutes.
Other battle-tested techniques are also powerful when used correctly. For example, decreasing allocation requests by avoiding pointers removes much stress from the system allocator; using custom allocators can benefit allocation speed and decrease memory fragmentation, etc.
Last but not least, know your domain and profile, benchmark your program to find the slowness root cause before optimizing, try multiple approaches, and repeat.
7. Further Read