
Table of contents
1. Introduction
2. Recurrent Neural Networks (RNNs)
3. Transformer to the rescue!
3.1. Attention
3.2. Transition to Transformer
4. Pretrained decoders and GPT
5. Conclusion
6. References
1. Introduction
Large language models (LLM) and ChatGPT have been a technical breakthrough in the field of Natural Language Processing (NLP) in the past few years. The idea of putting a little effort and a ton of text data into getting these models to learn and then surpass previous best models in many tasks which researchers have spent years to develop, is just fascinating. Outside of the AI community, people are amazed by the fact these models can generate text that is hard to distinguish from real human writing.
As a result, LLM applications are huge, everyone is using them and talking about them. I myself can not imagine how I can survive a day without using LLM: from facilitating my daily coding with Copilot to going over to AI Chatbot like ChatGPT or a recent Cốc Cốc AI Chat - https://aichat.coccoc.com (can not miss the opportunity to promote our product here 😄) to ask a few serious questions. But I think a question has to be in one's mind if they are not familiar with AI and NLP is: "Yeah we know it is called "Chat" because it is a chatbot and you can talk to it, but what does the other part "GPT" mean?". So in this blog, not only will I try to answer this question, but also give a brief introduction to some important milestones in the history of Language Models, the problems and obstacles people encountered to invent GPT and get to the exciting point where we are now.
Before any of that, let's get the most basic concept out of the way: Language modeling is the task of predicting what word comes next, based on the context of the preceding words. Given the following text as input: "The students opened their ___.", a language model might be confident that the next word is "books", resulting in the completed sentence: "The students opened their books". You probably have used language models in your daily life without even realizing it, for example when you type a message to your friend, you often see word suggestions pop up as you type, predicting what you might want to say next. Or when you use google search engine to find something on the internet, you often see suggestions for succeeding words or phrases based on the context of what you've already typed. These suggestions are generated by language models.
2. Recurrent Neural Networks (RNNs)
From around 2014 to 2017, Recurrent Neural Networks were the state-of-the-art (best) in language modeling. RNNs can process a sequence of inputs by repeatedly applying the same function for every element of the sequence, with the output being dependent on the previous computations as shown in Figure 1. Their hidden state allows them to remember some information about the previous inputs. This makes them well-suited for language modeling, since they can use the context of previous words to inform the prediction of the next word.
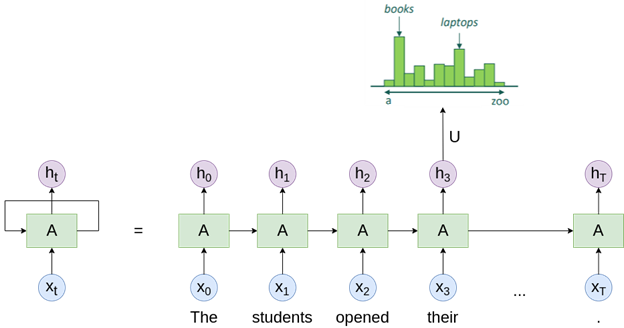
RNNs worked well in many tasks and were the backbone of many popular models at the time. However, people soon realized that RNNs have two major problems:
Firstly, they had trouble learning long-term dependencies between faraway words. They can encode linear locality, which means nearby words affect each other's meanings. This is actually useful because nearby words should influence each other. But if words are distant linearly, they can still interact with each other. For instance in Figure 2, RNN encodes "The chef who" and then a long sequence of words, and then the word "was". Maybe it is "The chef who ... was", but in between there are O(sequence_length) steps of the computation that need to happen before "chef" and "was" can interact.
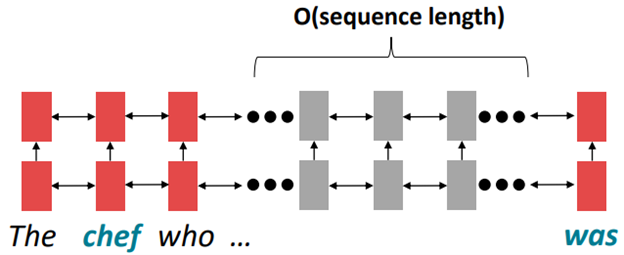
Secondly, recurrent computation is slow and lacks parallelism. Even nowadays we have GPUs that can perform numerous independent computations at once, but future RNN hidden states can not be processed before past RNN hidden states have been computed. This inhibits training on very large datasets.
For viewers who are interested in the topic, you can refer to this blog post [1].
3. Transformer to the rescue!
3.1 Attention
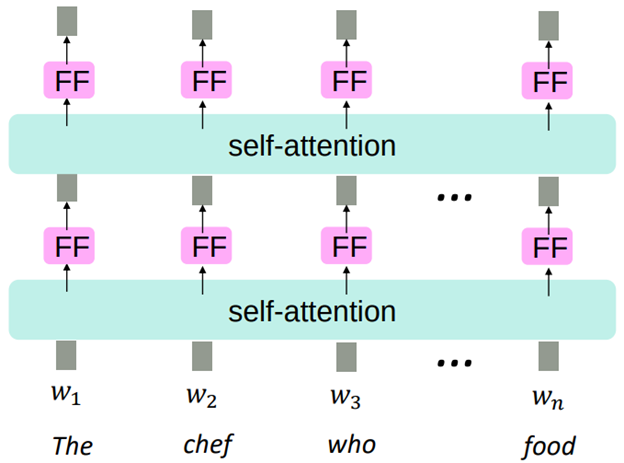
Attention refers to the ability of the model to attend to different parts of a sequence when making predictions. It allows a word in the current layer to attend to all words in the previous layer (Figure 3), and then decide which words are important to focus on via "attention weights". All words in the previous layer can attend to a word in the current layer, thus making attention a parallelizable operation. Moreover, the interaction distance between words is O(1), since all words interact at every layer. These two properties solve the two problems of RNNs mentioned above.
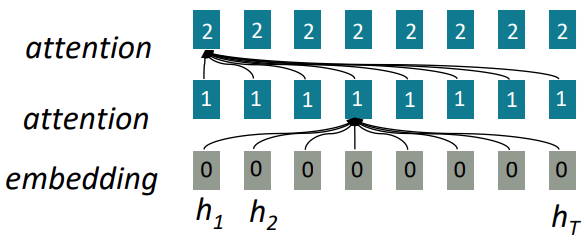
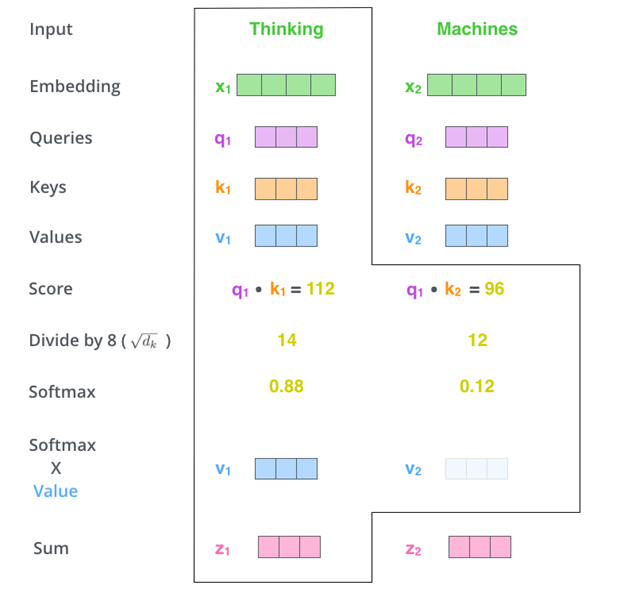
Self-attention is a specific type of attention, where it focuses on attending to different positions of the same input sequence. The intuition of its calculation on the word level is based on vector multiplications and averagings and can be easier to understand by referring to Figure 4. However, in practice, self-attention is done in matrix form for faster computation. I would highly suggest a blog post [2] about the topic if you want to know more about self-attention or Transformer in general.
3.2 Transition to Transformer
Self-attention is so great and can solve the two problems of RNNs, but can we use it to replace RNN as a building block of language models? Yes, but there are still a few issues that we need to solve to get there:
- Positional encoding: The self-attention equation is an unordered function of its inputs, therefore it does not know the order of input sentences. For example in Figure 5, without representation of position, the self-attention encoding for the input is "The chef who ... was" will be the same as the encoding for "Chef the who ... was" for the words "the" and "chef". But in fact we would want the encoding to be different, because the order in which words appear in sentences should matter to the word that is being encoded. A solution to this is adding position representation to the input, which is a matrix that gets to be learned to fit the data from scratch.
- Feed-forward network: Non-linearities are the key to the success of neural networks, making them much more powerful than linear models in learning complex patterns of data. But there are none of them in self-attention, all it does is re-averaging vectors. Stacking more of self-attention layers means more re-averaging. An easy fix is to apply the same feed-forward network to each self-attention output of every individual word, as shown in Figure 5.
- Masked attention: We need to ensure we don't “look at the future” when doing language modeling, because the purpose is to predict the next word based on the previous words. If the model cheats and looks at the future words that it is supposed to predict, it will not learn anything and we will train networks which are totally useless. To solve this, we mask out the future by setting attention weights to 0. In other words, we tell the model not to attend to future words when it tries to predict a word. For example in Figure 5, the model at position 2 when encountering the word "chef" can look back to the word "The", but it can't look forward to "who" and "food".
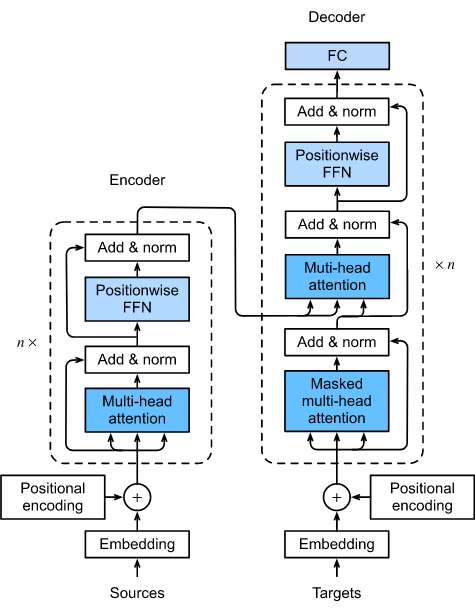
Put all of these together, we get the Transformer architecture (Figure 6) with an encoding component, a decoding component, and cross-attention connection between the output of the encoding component and decoder layers. The encoding component is a stack of n = 6 encoders and the decoding component is a stack of decoders of the same number.
4. Pretrained decoders and GPT
Ah, we now get to the part where I finally have all the pieces to answer the question at the beginning of this post.
Given the fact that in Transformer decoder, the masked attention only allows the model to attend to previous words, it is a natural fit for language modeling. You can use the Transformer decoder to pretrained on a huge dataset, and then fine-tune it on a smaller dataset for your specific task. The way you pretrained the model is to try to predict the next word given the context, and minimize the error between the prediction and the actual next word, which is illustrated in Figure 7. There is actually a lot of data for this because any text you can find on the Internet can be used for pretraining. And also you don't need to label the data, the model will use the next word as the label given the context as the input.

2018's GPT (stands for Generative Pretrained Transformer) was the first popular model in the line of pretrained decoders. It had 117 million parameters, with 12 decoder layers, 768-dimensional hidden state, 3072-dimension feed-forward hidden layers. GPT worked well as the starting point to finetune in many downstream NLP tasks. A year later, GPT-2, a larger version of GPT (1.5 billion parameters), pretrained on more data, was shown to produce relatively convincing natural language text. An even larger language model GPT-3 was then released in 2020 by OpenAI. With a whopping 175 billion parameters, it has the ability to perform in-context learning, which means learning to perform a task based on the few examples that are provided as part of its context, without the need for fine-tuning. For example, given a few examples of translation as a prefix (prompt), GPT-3 is then able to translate a new phrase from English to French. ChatGPT (GPT-3.5) is a variant of GPT-3 which has been optimized for conversation AI applications with the help of two additional phases: Supervised finetuning (SFT) for dialogue and Reinforcement Learning from Human Feedback. The what and how to pretrain and finetune models like ChatGPT is a difficult but exciting topic, and I will leave it to an expert in the field / ex Coc-Coc-er to explain in her blog [3].
5. Conclusion
To recap, this super long article has covered:
- the basic concept of language modeling
- the problems of RNNs and how Attention solves them
- the necessity additions to Attention to get to Transformer
- the idea of stacking Transformer decoders to form large language models and GPT
and hopefully answer many questions that you might have about language models and its evolution along the way. Language models and GPT are growing rapidly, and the new LLMs equipped with in-context learning have pioneered a new way of interacting with LLMs and leveraging their superpower into real-world applications. You may have heard of the term "prompting" and "prompt engineering" in the context of LLM application development, which refer to the process ...
It will be another post if I continue writing, so I will instruct my "language model" to stop here. Hope to see you in the next one!
6. References
[0] CS224N: Natural Language Processing with Deep Learning, https://web.stanford.edu/class/cs224n/.
[1] Christopher Olah, Understanding LSTM Networks, http://colah.github.io/posts/2015-08-Understanding-LSTMs/
[2] Jay Alammar, The Illustrated Transformer, June 27, 2018, http://jalammar.github.io/illustrated-transformer/.
[3] Chip Huyen, RLHF: Reinforcement Learning from Human Feedback, May 2, 2023, https://huyenchip.com/2023/05/02/rlhf.html.