
An establishment of the Entity Name Dictionary
1. Introduction
Given an upward trend of digital conversion from traditional retail channels [1], our goal is to support an e-commerce platform with a system of price comparison among available products across different retailers. To do this, it is crucial to detect identical or significantly similar products from many e-commerce sites. One possible approach is to extract entity information and then use them as criteria for the product-matching process. To develop an automatic Named Entity Recognition (NER) framework, we are expected either to make use of an existing benchmarking dataset of millions of product titles with tagged attributes or instead to have complete lists of names for further linguistic analyses. Unfortunately, neither was our situation – especially for product names considered the most important.
While public collections of product information (descriptions, titles, …) are available on the internet where product attributes are extracted as named entity tags, we do not have any large-scale ones in Vietnamese. Since the sizes of necessary Vietnamese datasets need to be taken into consideration, it is impracticable to manually tag several products attributes on millions of product titles. As a result, this lack of entity name dictionaries and benchmarking datasets requires our effort to propose a method to recognize product entities from listing titles at high confidence levels in different categories. In this blog, we will focus on product name extraction and describe how to build entity name dictionaries of them from product titles.
2. Data
To obtain a benchmarking dataset for the training of the Product Attribute Extraction NER framework, we started by downloading millions of product data from muarenhat.vn, which crawls data from many large e-commerce platforms in Viet Nam such as Tiki, Shopee, and Lazada. Overall, we collected around 2 million product listings across multiple brands and 29 categories as in Table 1.
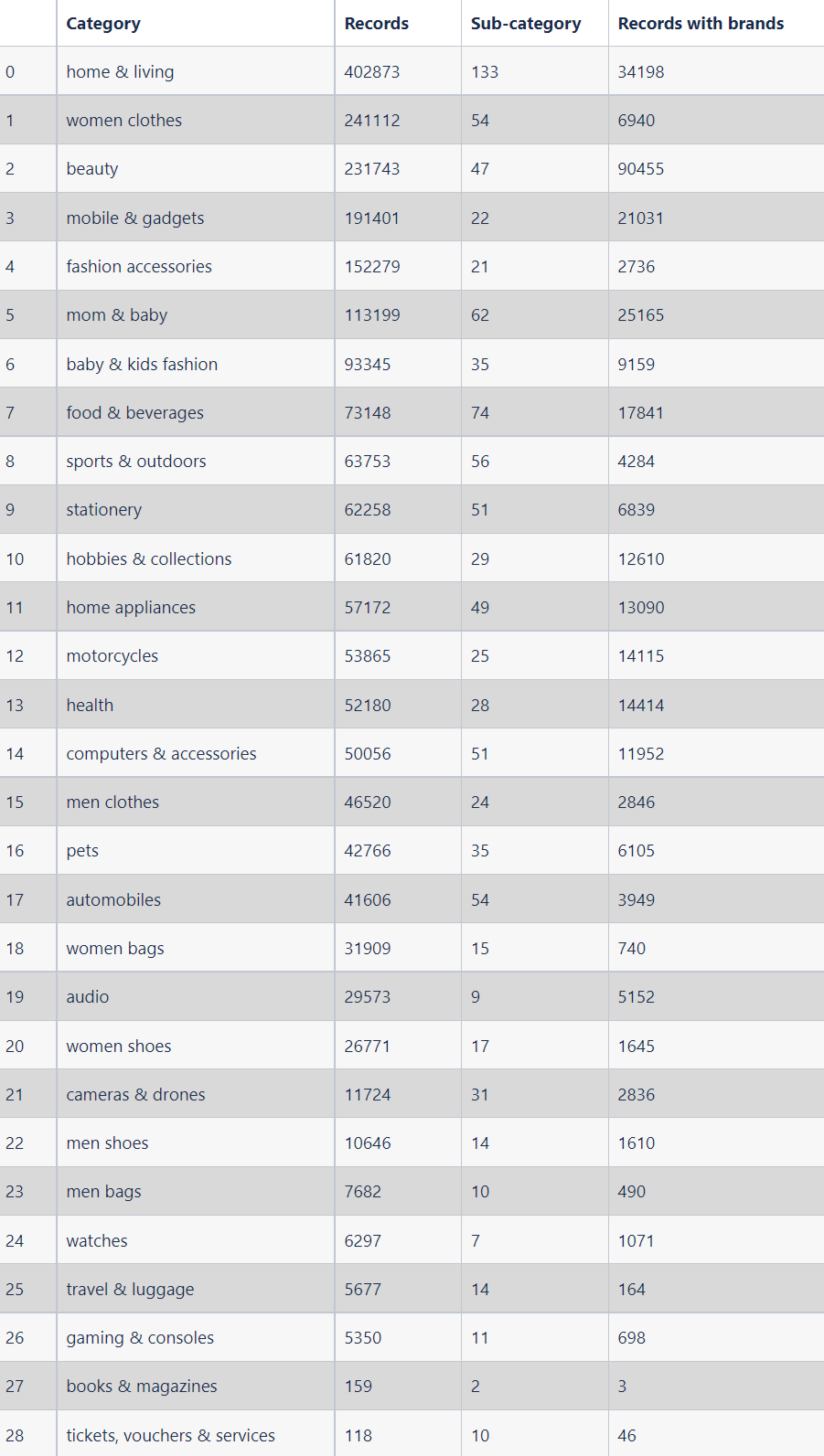
Table 1: A summary of the number of records, the number of sub-categories, and the number of records with provided product brands in 29 product categories from the database.
3. Procedure
3.1 A general framework for the dictionary establishment
In Figure 1, we summarized four main sub-processes to be able to gather all product names from our databases. Since our purpose was to establish a collection of product names per product category as complete as possible, we chose to prioritize name accuracy over coverage. We proposed four steps to extract those lists as follows.
- Step 1: extract O-typed parts of product titles
- Step 2: group similar titles and extract keywords
- Step 3: analyze the positions of extracted keywords
- Step 4: define confidence scores of being product names on the extract keywords

Figure 1: A procedure to extract lists of product names from product sub-categories.
3.2 Extraction of O-typed product title
Let us introduce two similar processes that inspire the use of the NER framework for the extraction of product attributes: Part-of-Speech Tagging, and Named Entity Tagging [2]. In the first process, Part-of-Speech Tagging assigns each word in a text to a part of speech, whether it is a noun (NOUN), verb (VERB), auxiliary AUX, and so on. On the other hand, the second process (Named Entity Tagging) recognizes the terms of certain named entities such as a person (PER), location (LOC), or organization (ORG). Thus, in the same approach, we expect a product title will contain a series of attributes: product names, product brands, product codes, product sizes, colors, target genders, ages, and other descriptive characteristics of products (colors, shapes, printed patterns, etc). Since our main focus is on product names (N), the first step that needs to be taken is to extract parts of titles that are likely to contain N(s).

Figure 2: An example of a product title of 13 terms with extracted attributes.
To do so, we attempted to extract as many attributes as possible over every product title: (i) product brands (B), (ii) product sizes (S), (iii) product codes (C), (iv) mixed attributes including less essential information such as discount and quantities inside brackets (M), (v) product colors (Color), (vi) targeted genders (G), (vii) targeted ages (Age), and finally (vii) unidentified attributes (O). Except for the last attribute (O), we could identify the other attributes by using provided dictionaries (B, G, Age) as well as regex patterns (C, S, etc). Naturally, the unidentified attribute (O) was likely to contain product names. In Figure 2, we gave an example of a product title containing 13 terms: W0 to W12. By using provided information and regex patterns, we managed to identify M for W0-W2, B for W5, C for W6, Color for W7, Age for W9, and G for W12. Therefore, we expect N to be among the remaining terms: W3-W4, W8, and W10-W11. To be more specific, we showed a real example as follows.

In this example, we aimed to extract parts of the product title “ốp lưng Huawei gr5 mini in hình theo yêu cầu" that are likely to contain its product name(s). Since two attributes are identified: product brands (B) for "Huawei", and product codes (C) for "gr5" and "mini", we will process only the remaining terms with 'O' tags - "ốp lưng in hình theo yêu cầu" for further analyses.
In summary, the remaining sub-sections will use the O-typed parts of product titles for the establishment of dictionaries for product names.
3.3 Title clustering and keyword extraction
In this sub-section, our expectation was that ‘similar’ product titles would likely involve similar products, and therefore they would contain the same product names. In other words, if we could determine every group of similar product titles and extract their commonly used terms, we could gather all product identifier terms.
3.3.1. Methodology
Considering every n-grams across all products sub-categories usually remains significantly exhaustive even for a small value of n. The trickiest task for us here was to handle an unknown number of product names as well as an unknown number of their synonyms over millions of product titles. As a result, we first grouped similar product titles together and then extract a small number of commonly used terms. These frequently used n-grams of each title cluster were likely to identify the product very clearly, and therefore could be considered product names.
To cluster titles, we applied the method that combines Minhashing and Locality Sensitive Hashing (LSH), which reduces the cost of computation significantly in performing pairwise comparisons in corpus [3]. Minhashing was applied not at the token level but at the character-level trigram, and Jaccard similarity Jk ranged from 0.3 to 0.9 in steps of 0.1. In each value of Jk, we obtain a number of clusters, nk containing at least 3 product titles. In a given group, we determine the list of n-grams (1 < n < 9) that their numbers of occurrences lie in the top 10% of the group. We then extract the n0 = 2 top longest n-grams from the list. With all extracted terms, we defined the detection score of a given term wi, S(wi)to be:
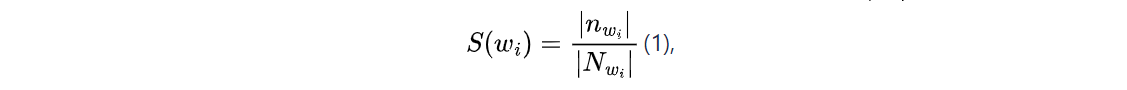
where S(wi) is the detection score (at Jk) for the term wi, Nwi = {dj} is a set of titles that contain wi, and Nwi is the set of titles that wi is extracted as the keyword by the method, nwi ⊂ Nwi. This detection score merely measures the rate of labeling wi as the keyword for product titles that contain wi. Our expectation was that good clustering and keyword extraction would result in a majority of high-score n-grams.
3.3.2. Results on title clustering and keyword extraction
By implementing the Minhashing LSH method on every sub-category of all product categories, we obtained a different number of clusters at different values of Jk. In Figure 3, we showed the number of groups of similar product titles and a respective number of distinct keywords extracted for a given value of Jk, 0.3 < Jk <0.9 for a subset of the Mobile & Gadgets - accessories - cables, chargers & converters sub-category.
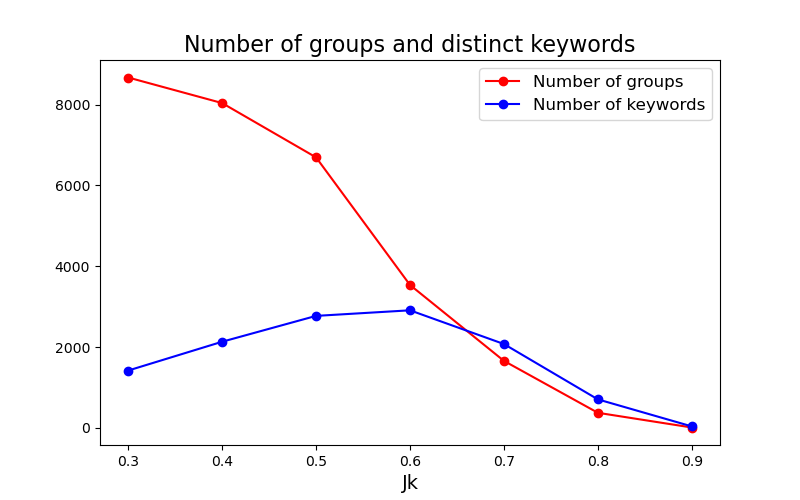
Figure 3: The number of groups and the number of keywords in each value of Jk in a subset of the Mobile & Gadgets - accessories - cables, chargers & converters sub-category.
It was expected that the number of title groups decreased when the value of Jk increased, but we could see the number of distinct keywords peaking at Jk = 0.6. Next, we adopted a visualization method in [4] to show the top 3-gram keywords in every value of Jk ∈ {0.3,...,0.8} (Figure 4). Here, we want to examine whether the value of Jk might have an impact on the accuracy of extracted terms as product identifiers.
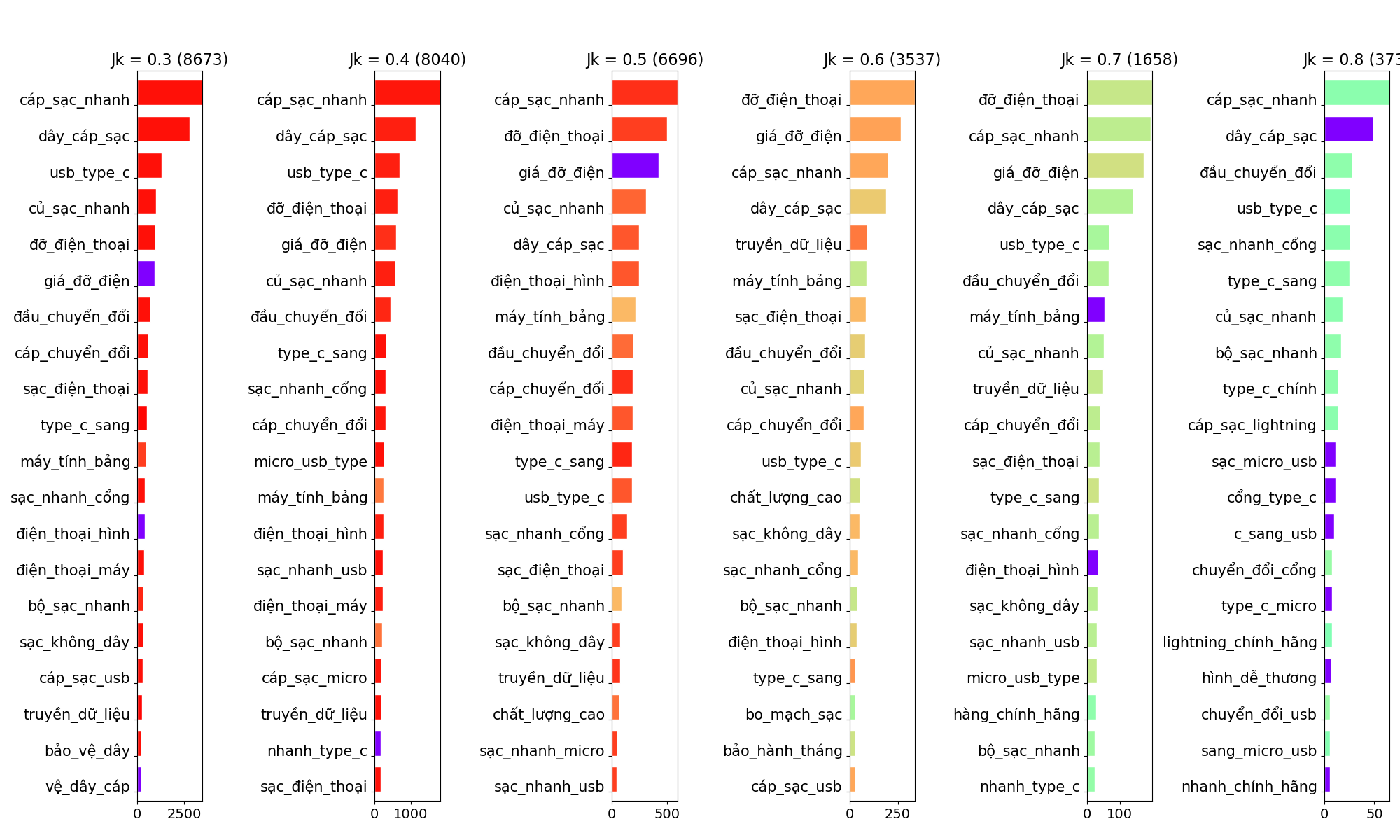
Figure 4: The top 3-grams in each Jk where the length of a 3-gram’s bar indicates its number of occurrences in all groups of product titles, and the color indicates its detection score calculated by Equation 1 (red ~ 1, purple ~ 0).
Figure 4 illustrated both the frequencies of the top 3-grams and their confidence scores, S(wi). Firstly, it was clear that our expectation on high S(wi) of those extract n-grams failed for Jk ≥ 0.6. Secondly, there existed terms at both high frequencies and confidence scores to be irrelevant to product names, i.e. “type_c_sang”, “chất_lượng_cao”, “bảo_hành_tháng”, “hàng_chính_hãng”, etc. Therefore, we believed a second filtering process was needed to distinguish between product names and other common terms from all extracted keywords.
3.4 Position analysis
From the previous sub-section, we would need to examine different characteristics among n-grams. We would like to start with a simple method on the position of the terms at the titles to evaluate their importance. Since product titles usually are combinations of nouns, verbs, and adjectives without strict requirements on syntactic structures, we made an assumption: terms with the same functions are likely to appear at similar positions. In other words, if those extract all keywords identify product names, their distribution of positions should be the same on average.
To validate, we divided an O-type product title length into 12 bins and determined the bin-location of every extracted n-grams. If a given term was usually used at the beginning or in the end of most of the product titles, it would have a skewed location distribution (left-model or right-model). On the other hand, if it appeared randomly over the titles, we expect the distribution of its average position would be uniform. It is expected that differences in the location distributions between n-grams can help us identify which n-grams are indeed product names. In Figure 5, we showed an example of the distribution of average locations of the top n-grams from Mobile & Gadgets - accessories - cables, chargers & converters.
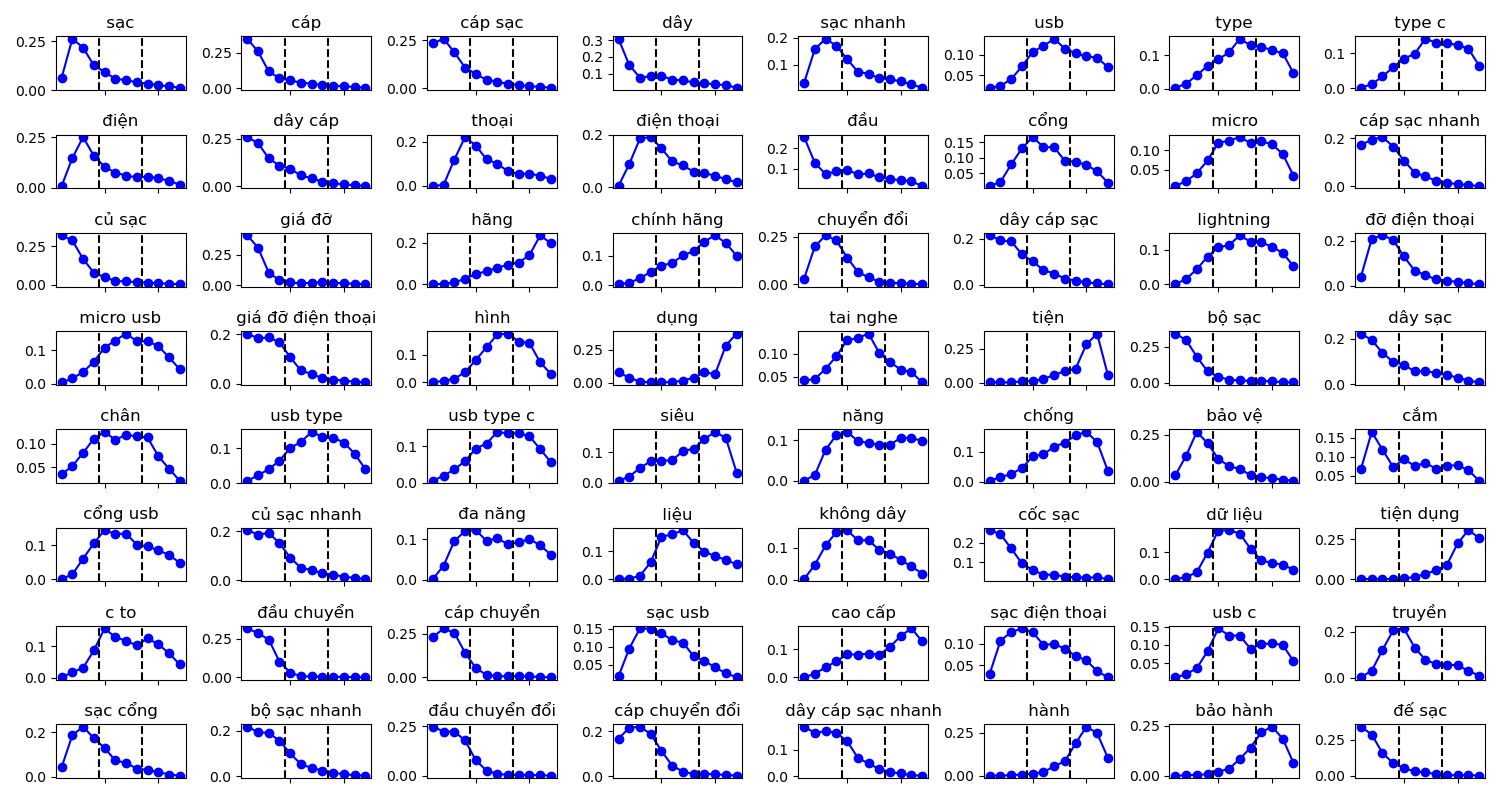
Figure 5: The position distribution of the top extracted n-grams in the Mobile & Gadgets - accessories - cables, chargers & converters sub-category.
From Figure 5, we suspected terms that were usually located near the start of product titles to be the product names. Therefore, we believed it would be suitable to evaluate the confidence level of an n-gram to be a product identifier based on two properties as follows.
- The average location of the n-gram across all product titles on the same (sub) categories, and
- The real location of the n-gram on a given title.
In other words, every term will have a unique confidence score on a given product title determining how likely it is actually the product name.
3.5 Confidence score of identified product names
In this sub-section, we proposed a method to calculate the confidence score of a given n-gram to be the product name based on its location on a given title as well as its average location across all product titles containing it. Here, let wi represent an n-gram and let di represent a given product title i containing wi. If we divided the length of di into 12 bins as {bki} k ∈ {1,2,...,12}, we could identify which bins contain wi, {bk*i} k*. For instance, in Figure 6 we gave an example of a considered n-gram wk belonging to three bins of a product title, { b4, b5, b6 }.

Figure 6: An example of a given title of 12 bins in which n-gram wk belongs to three bins, { b4, b5, b6 }
By collecting all product titles containing an extracted n-gram wk, we could calculate its normalized distribution of the average location as follows.
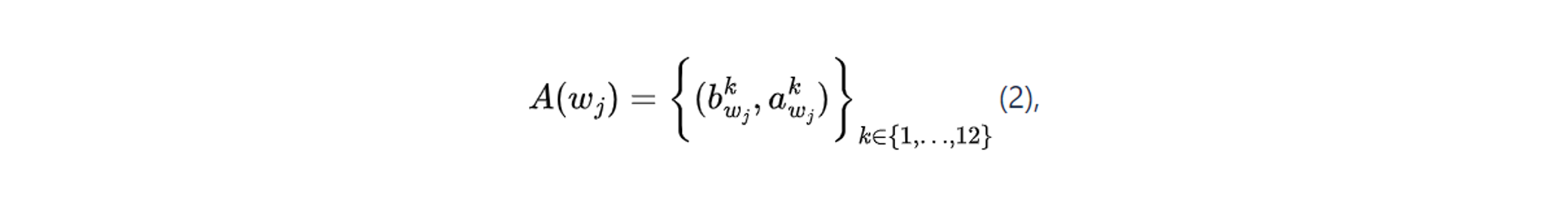
where A(wj) is the distribution of the average location of wj, bkwj, is the bin-location k, akwj, is the average proportion of term wj on bin k that
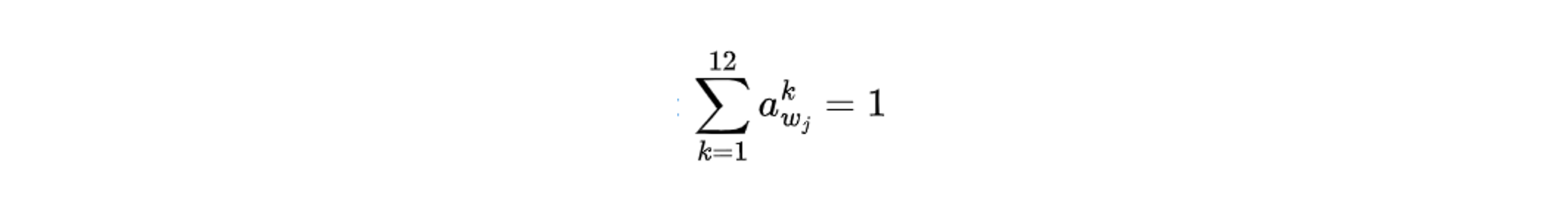
We believed a combination of the real location, {bk*i} k*, and the average location, A(wj) could determine the confidence score of wj to be the product name.
Let S1(wj) be the average-location score, and S2(wj) be the real-location score of wj on a given title di. The value of S1(wj) is calculated as the area under A(wj) as if wj was located at the beginning of di. On the other hand, S2(wj) is calculated as the area under A(wj) from its real bin-location,{bk*i} k* . In Figure 7, for a given n-gram wk involving in three bins { b4, b5, b6 }, S1(wk) is calculated as the blue area over { b1, b2, b3 }, and S2(wk) is calculated as the red area over { b4, b5, b6 }.
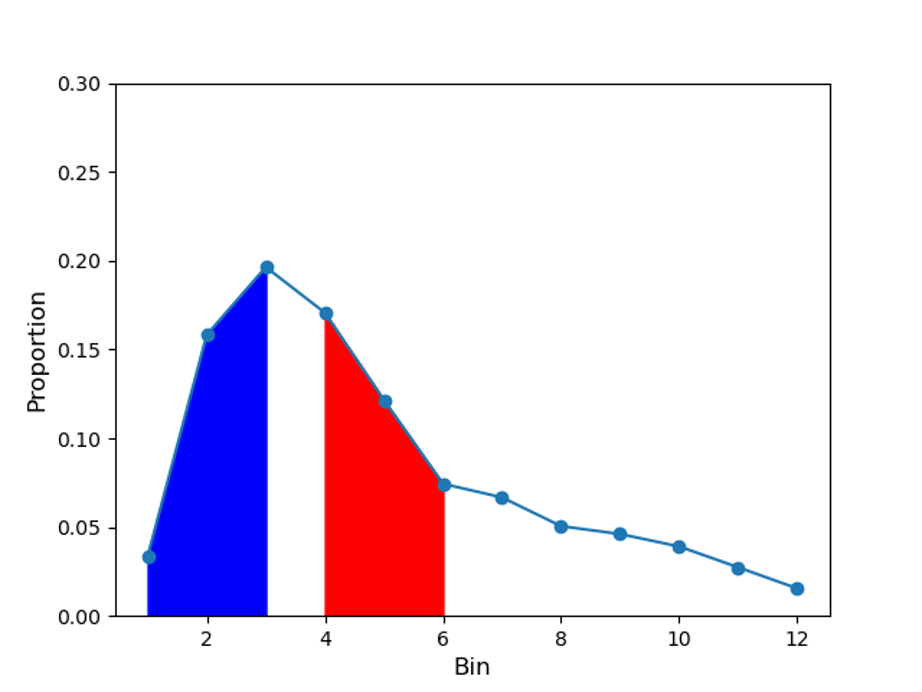
Figure 7: A example plot of A(wk), the blue area is for bins { b1, b2, b3 } and the red area is for bins { b4, b5, b6 }.
To incorporate both scores, S1(wj) and S2(wj) for a given n-gram wj, we used a parameter c (0 ≤ c ≤ 1) so that the combined confidence score S*(wj) for wj is as follows.
S*(wj) = (1-c).S1(wj) + c.S2(wj) (3),
At high c: a high confidence score S*(wj) on di indicates that wj locates at its average position, and
At low c: a high confidence score S*(wj) on di indicates wj locates at the beginning of di, regardless of its positions at other titles.
3.6 Establishment of dictionaries for product names
From Section 3.4, we understand how to assign a confidence score on each extracted n-gram based on both its real position on a given title as well as its average position across all titles containing it. We can also use parameter c ∈ [0,1] to reflect our preference for the position as well.
Since our purpose is to extract product names from every product sub-category at high accuracies, we do not need to worry about the coverage at the title level. In other words, it would be acceptable to miss product names on some titles as long as we could determine those accurate ones overall. As a result, we chose a low value of c, i.e. c = 0.1, to prioritize n-grams located near the beginning. After that, we applied a selection process of two steps to collect product names in each sub-category as follows.
1. Choose n-grams whose numbers of occurrence across all product titles are at least 5,
2. From all chosen n-grams in (1), choose the longest n-grams in each title and then
a. Extract only the top 2 n-grams in terms of their confidence scores, S*(wj)
b. Across those extracted n-grams, choose n-grams with an average confidence score of at least 0.5 and the maximum confidence score of at least 0.8.
In Figure 8, we showed an example of an n-gram tree for ‘dây’ - a popular term from the Mobile & Gadgets - accessories - cables, chargers & converters sub-category. We would like to emphasize that this tree had already been shortened due to a large number of related terms. The expected outcomes of this sub-section are the product name dictionaries across all product sub-categories.
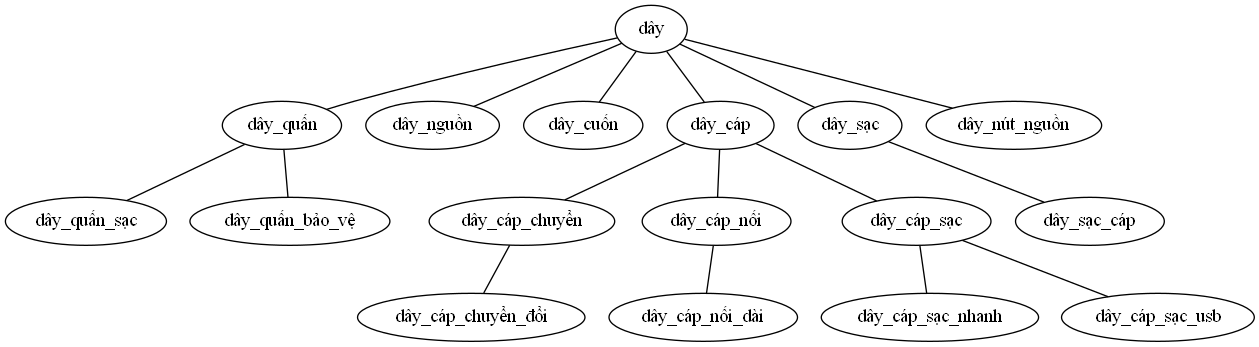
Figure 8: A shortened n-gram tree for the term ‘dây’.
4. Conclusion
In this blog, we described a framework (1) to detect locations and patterns of product attribute entities, and (2) to build product family trees as well as product dictionaries from a collection of product titles. This framework can be applied not only for product name entities but also for other entities such as product materials or product colors. In general, we proposed an evaluation on the confidence level of an n-gram to be the named entity based on (i) its frequency over title groups and (ii) its average position across every title. In summary, the product name dictionaries obtained from this procedure contribute to the construction of a NER system for product attribute extraction, in both rule-based and machine-learning approaches. We will discuss further these analyses with sample codes and datasets in the future blog.
5. Reference
[1] Yang, S., Lu, Y., Zhao, L., & Gupta, S. (2011). Empirical investigation of customers’ channel extension behavior: Perceptions shift toward the online channel. Computers in Human Behavior, 27(5), 1688-1696.
[2] Jurafsky, D., & Martin, J. H. (2020). Sequence labeling for parts of speech and named entities. Speech and Language Processing.
[3] Supriya Ghosh, Text Similarity using K-Shingling, Minhashing, and LSH(Locality Sensitive Hashing), https://pub.towardsai.net/text-similarity-using-k-shingling-minhashing-and-lsh-locality-sensitive-hashing-8a60a7aaa9d9
[4] Nguyen, A. L., Liu, W., Khor, K. A., Nanetti, A., & Cheong, S. A. (2022). The emergence of graphene research topics through interactions within and beyond. Quantitative Science Studies, 1-37.